时间并不真实存在,而如果时间非实在,世界与永恒、苦难与极乐,善与恶的界限亦皆为幻象。 ——赫尔曼·黑塞《悉达多》
写在前面
博文内容涉及Linux 内存调优的常见知识点,包含以下内容
认识 Linux 内存构成虚拟内存与物理内存
进程内存使用量的监控
系统内存的全局监控
利用BPF 观测 Linux 内存情况
如何限制内存使用量
OOM Killer 认知
博文没有具体的生产内存调优场景,只是提供了对应的知识点Demo,理解不足小伙伴帮忙指正,篇幅较长,适合收藏
时间并不真实存在,而如果时间非实在,世界与永恒、苦难与极乐,善与恶的界限亦皆为幻象。 ——赫尔曼·黑塞《悉达多》
认识 Linux 内存构成:虚拟内存与物理内存 计算机中的进程小伙伴一定不陌生,一般情况下一个应用会启动一个主进程,若干个子进程或者线程,每个进程都有一个内存地址空间用于存放当进程的一些共享数据,所以在进程启动时会请求一定大小的内存,这里的内存不是实际的物理内存地址,不直接定位物理内存。相反,是一块虚拟内存空间,内核会在进程地址空间中的虚拟地址空间和物理地址做一个映射来达到访问物理内存的目的。
比如在 Java 启动参数中,-Xms(Initial Heap Size)指定的 JVM 堆的初始大小是虚拟内存(Virtual Memory)的大小,而非直接对应物理内存的分配
1 java -jar -Xms1G -Xmx4G arthas-boot.jar
JVM 向操作系统申请 1GB 的虚拟地址空间(对应 VIRT 的一部分)。物理内存占用可能仅为 100MB(取决于 JVM 初始化时的实际内存需求)。
那么这里的虚拟地址空间到物理内存地址的映射是什么?
内存虚拟地址空间物理地址映射 首先这里的虚拟空间地址大小由`处理器架构位数决定
在x86_64的 64 位系统上面,理论的内存地址就是 16EiB(2^64) 的大小。但实际实现中受硬件架构和操作系统设计的限制,仅部分地址位被有效利用,硬件层面通过符号扩展机制仅支持 48 位虚拟地址(低 48 位),高 16 位(48-63)需填充为第 47 位的值,形成规范地址(Canonical Address),实际可寻址空间为 256 TB(2^48 字节),分为两部分:
用户空间:0x0000000000000000 至 0x00007FFFFFFFFFFF(128 TB)内核空间:0xFFFF800000000000 至 0xFFFFFFFFFFFFFFFF(128 TB)
Linux 系统默认使用完整的 48 位地址,但用户进程实际可用空间通常更小(如通过 TASK_SIZE_MAX 限制为 128 TB 减去保护页)
在 Linux 系统中查看 /proc/cpuinfo 时,address sizes 字段描述了 CPU 的物理地址和虚拟地址的寻址能力
1 2 3 4 5 6 ┌──[root@liruilongs.github.io]-[~] └─$cat /proc/cpuinfo | grep address address sizes : 45 bits physical, 48 bits virtual address sizes : 45 bits physical, 48 bits virtual ┌──[root@liruilongs.github.io]-[~] └─$
45 bits physical:表示 CPU 可以寻址的物理内存空间大小,决定了 CPU 能直接访问的最大物理内存, 2^45 字节,CPU 理论上最多支持 32 TiB 的物理内存
48 bits virtual:表示 CPU 的虚拟地址空间大小。决定了单个进程能使用的最大虚拟内存空间,2^48 字节,每个进程的虚拟地址空间上限为 256 TiB(操作系统通过虚拟内存机制将虚拟地址映射到物理地址或磁盘交换空间)。
所以进程虚拟地址空间的大小不取决于安装的物理内存大小 RAM,而是取决于处理器架构,单个进程通常不使用其整个地址空间。其中大部分是未分配的,并且没有映射到任何实际的物理内存。
其次进程在通过虚拟地址空间访问物理内存时
通过多级页表实现虚拟→物理地址转换,通过内存管理单元(MMU)执行实时地址转换与访问权限校验,同时支持按需分页(Demand Paging)机制延迟物理页帧分配.
1 2 3 4 5 进程访问虚拟地址 → MMU 查询 TLB → [命中 → 直接获取物理地址] │ └→ [未命中 → 查询页表 → 权限检查 → 缺页处理(可选)→ 生成物理地址 → 更新 TLB] │ └→ 访问物理内存
这里的多级页表和MMU是什么?
多级页表和MMU 处理器架构定义的标准内存单元为页面(Page),在x86_64架构中采用固定大小4 KiB(4096字节),计算机系统将内存组织为固定大小的块,这里的块就是页面,或者叫页帧。页表用来存储虚拟页到物理页帧的映射,由操作系统 MMU 维护的数据结构。MMU(Memory Management Unit)内存管理单元.
多级页表:现代系统使用多级页表(如 x86-64 的 四级页表),逐步缩小搜索范围。
虚拟地址拆分:虚拟地址被分割为多个索引字段,逐级查询页表项(PTE),48 位虚拟地址可能拆分为:PGD索引(9位) → PUD索引(9位) → PMD索引(9位) → PTE索引(9位) → 页内偏移(12位)
进程通过页表查询虚拟地址和物理地址的映射关系, 首先会检查 TLB 缓存,TLB(Translation Lookaside Buffer)高速缓存页表项的硬件缓存
命中(TLB Hit):若 TLB 中存在该虚拟地址对应的物理地址,直接使用缓存结果,跳过页表查询。未命中(TLB Miss):若 TLB 中无缓存,需查询页表。
在实际的查询之前,还有一个验证页表项的步骤,主要进行权限检查,MMU 检查页表项的权限(如读/写/执行、用户/内核模式权限)
虚拟地址分页号和偏移量,页面定位页表中的对应索引位置,根据页面查询到物理地址的起始位置,然后再通过偏移量找到具体的数据, 如果权限违规,会触发 段错误(Segmentation Fault)(例如尝试写入只读页,栈溢出,虚拟内存溢出之类)。
看一个Demo,通过 ulimit 模块设置单个单个进程栈大小为 16
1 2 3 4 5 ┌──[root@liruilongs.github.io]-[~] └─$ulimit -s 16 ┌──[root@liruilongs.github.io]-[~] └─$ulimit -a | grep stack stack size (kbytes, -s) 16
运行 ls /etc/ 命令时,发生了段错误,这里实际会生成了一个核心转储文件。
1 2 3 ┌──[root@liruilongs.github.io]-[~] └─$ls /etc/ Segmentation fault (core dumped)
上面设置了 栈的大小,所以执行的命令存在栈溢出的情况,也可以通过 ulimit 配置虚拟内存大小,进程在初始化阶段(如加载自身代码或动态链接器)就耗尽虚拟地址空间。
1 2 3 4 5 ┌──[root@liruilongs.github.io]-[~] └─$ulimit -v 1024 ┌──[root@liruilongs.github.io]-[~] └─$ls Segmentation fault
当启动一个程序时,先给程序分配合适的虚拟地址空间,但是不需要把所有虚拟地址空间都映射到物理内存,而是把程序在运行中需要的数据,映射到物理内存,需要时可以再动态映射分配物理内存
因为每个进程都维护着自己的虚拟地址空间,每个进程都有一个页表来定位虚拟内存到物理内存的映射,每个虚拟内存也在表中都有一个对应的条目,
当进程访问虚拟地址,但是在页面中查不到时,内核就会产生一个缺页异常(Page Fault)内核此时会重新分配物理内存,更新页表。
所以在验证页表项通过之后,查询页表数据标记为不存在,会促发缺页中断,会重新分配物理页帧(从空闲内存或通过页面置换算法如 LRU 淘汰旧页),或者磁盘(如交换分区或文件)加载数据到物理页帧,更新页表项,标记为有效,重新执行触发缺页的指令。
通过页表项获得物理页帧基地址,加上虚拟地址中的页内偏移,得到最终物理地址。MMU 将物理地址发送到内存总线,CPU 读取或写入物理内存。
监控进程的内存使用量 这里分析的工具主要是原生工具,后面还会分享一些 BPF 相关的内存观察工具以及内存的全局监控
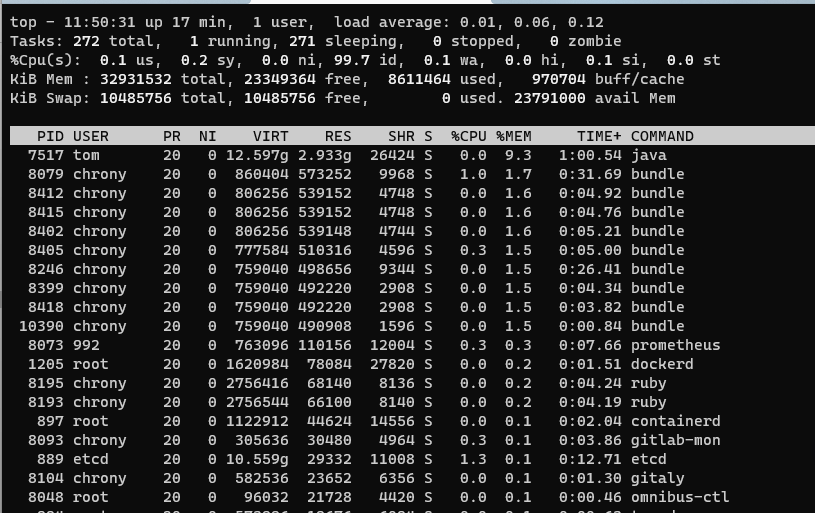
PS/TOP 一般的内存监控工具,对于进程级别的,会使用如 ps/top 命令, 通过指标 VIRT 或 VSZ 和 RES 或 RSS 来区分两种不同的统计数据
VIRT 或 VSZ 代表进程申请的虚拟内存大小,RES 或 RSS 代表的是虚拟内存当前实际映射的物理内存大小,也叫常驻内存。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 ┌──[root@vms100.liruilongs.github.io]-[~] └─$top top - 11:46:44 up 8 min, 1 user, load average: 6.52, 17.45, 10.38 Tasks: 449 total, 1 running, 448 sleeping, 0 stopped, 0 zombie %Cpu(s): 0.9 us, 1.1 sy, 0.0 ni, 96.8 id, 0.0 wa, 0.6 hi, 0.5 si, 0.0 st MiB Mem : 15730.5 total, 7503.6 free, 7147.4 used, 1079.5 buff/cache MiB Swap: 2068.0 total, 2068.0 free, 0.0 used. 8177.7 avail Mem PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 1947 42418 20 0 555196 132972 20272 S 1.3 0.8 0:12.86 heat-engine 10320 42436 20 0 540276 122200 17492 S 1.3 0.8 0:08.95 nova-scheduler 949 root 20 0 694072 31640 16876 S 1.0 0.2 0:16.58 tuned 。。。。。。。。。。。。。。。。。。。。。。。。。 15567 root 20 0 269540 5228 4160 R 1.0 0.0 0:00.05 top ..........................................
所以如果通过上面的命令,查看应用实际使用的内存大小,需要查看 RES(RSS(KB单位)) 列,表示进程当前驻留在物理内存中的内存总量(即没有被交换到磁盘的部分)。
RSS 包含的内容:
进程独有的数据(如堆、栈、私有匿名页)。
1 2 3 4 5 6 7 8 9 10 11 12 ┌──[root@liruilongs.github.io]-[~] └─$ps -e -o pid,vsz,rss,comm | awk '$2 > 0 {print}' PID VSZ RSS COMMAND 1 170808 14208 systemd 704 26824 11520 systemd-journal 719 34968 12160 systemd-udevd 892 18156 4540 auditd 913 10796 4736 dbus-broker-lau 。。。。。。。。。。 4177 6664 3712 awk ┌──[root@liruilongs.github.io]-[~] └─$
共享内存
需要说明的是,进程是共享物理内存页帧的。比如使用相同库函数的两个进程,就可以共享使用相同的物理内存页来存储库文件代码。它们各自的 RSS(Resident Set Size) 值会将该共享页的物理内存(SHR 列)重复计入每个进程的 RSS(RES)。因此 进程的 RSS 总和 可能会明显超过 系统实际的物理内存容量。真实物理内存占用 = 独占内存(RES) - 共享内存SHR(Shared Memory)。
SHR列 :进程占用的 共享物理内存(如共享库、共享内存 IPC)。
Cgroup 子系统 通过 Cgroup 子系统来获取内存信息,在获取之前需要获取当前进程的PID以及对应的 Cgroup 分组
获取 htop 进程ID, htop 是一个类似 top 的系统整体性能监控的进程
1 2 3 ┌──[root@liruilongs.github.io]-[/usr/lib/systemd/system] └─$pgrep htop 4150
通过 ps 命令获取 htop 对应的 Cgroup 分组
1 2 3 4 5 6 7 8 9 ┌──[root@liruilongs.github.io]-[/usr/lib/systemd/system] └─$ps -o cgroup 4150 CGROUP 11:pids:/user.slice/user-1000.slice/session-1.scope, 8:memory:/user.slice/user-1000.slice/session-1.scope, 2:devices:/user.slice, 1:name=systemd:/user.slice/user-1000.sli ┌──[root@liruilongs.github.io]-[/usr/lib/systemd/system] └─$
我们只关注内存子系统的,所以直接看内存的分组: 8:memory:/user.slice/user-1000.slice/session-1.scope,这里的 8 表示 Cgroup 层级
可以通过下面的命令查看 Cgroup 层级以及 当前系统挂载了多少子系统
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 ┌──[root@liruilongs.github.io]-[/usr/lib/systemd/system] └─$cat /proc/cgroups cpuset 4 1 1 cpu 6 3 1 cpuacct 6 3 1 blkio 9 1 1 memory 8 91 1 devices 2 43 1 freezer 13 1 1 net_cls 12 1 1 perf_event 5 1 1 net_prio 12 1 1 hugetlb 7 1 1 pids 11 52 1 rdma 3 1 1 files 10 1 1 ┌──[root@liruilongs.github.io]-[/usr/lib/systemd/system] └─$
user.slice/user-1000.slice/session-1.scope 表示 Cgroup 层级树
user.slice:表示该 cgroup 属于 用户会话层级,与用户进程相关(与 system.slice 系统服务层级区分)user-1000.slice:表示用户 ID 为 1000 的普通用户(Linux 中 UID 1000 通常是首个创建的非 root 用户)session-1.scope:表示该用户的 会话单元(如一个终端会话或登录会话),属于临时性资源组(scope 用于管理短生命周期的进程组)
htop 是一个前台进程,通过 Cgroup 资源树可以很清晰的看到,下面来看下 Cgroup 内存子系统观察进程内存信息的一些指标文件
内存详细信息指标监控 下面一组是内存详细信息的数据统计
参数
作用
memory.numa_statNUMA 节点的内存使用统计 (适用于多 CPU 架构)。
memory.stat详细内存使用统计
在这之前我们先介绍一个特殊的值,memory.limit_in_bytes 这个可能是我们接触最多的参数,用于进程 物理内存资源限制
1 2 3 ┌──[root@liruilongs.github.io]-[/usr/lib/systemd/system] └─$cat /sys/fs/cgroup/memory/user.slice/user-1000.slice/session-1.scope/memory.limit_in_bytes 9223372036854771712
可以看到上面的 htop, 文件中的值 9223372036854771712 表示当前 cgroup 的内存限制处于无限制状态,当 cgroup 未显式设置内存限制时,内核会默认将此值设为 PAGE_COUNTER_MAX,该值由内核通过 LONG_MAX / PAGE_SIZE * PAGE_SIZE 计算得出,确保与内存页对齐.
memory.stat
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 ┌──[root@liruilongs.github.io]-[/usr/lib/systemd/system] └─$cat /sys/fs/cgroup/memory/user.slice/user-1000.slice/session-1.scope/memory.stat cache 393973760 rss 301170688 rss_huge 171966464 shmem 847872 mapped_file 86605824 dirty 8192 writeback 0 swap 0 pgpgin 241505 pgpgout 113977 pgfault 231305 pgmajfault 260 inactive_anon 302727168 active_anon 147456 inactive_file 348233728 active_file 44892160 unevictable 0 hierarchical_memory_limit 9223372036854771712 hierarchical_memsw_limit 9223372036854771712 total_cache 393973760 total_rss 301170688 total_rss_huge 171966464 total_shmem 847872 total_mapped_file 86605824 total_dirty 8192 total_writeback 0 total_swap 0 total_pgpgin 241505 total_pgpgout 113977 total_pgfault 231305 total_pgmajfault 260 total_inactive_anon 302727168 total_active_anon 147456 total_inactive_file 348233728 total_active_file 44892160 total_unevictable 0 ┌──[root@liruilongs.github.io]-[/usr/lib/systemd/system] └─$
以下是关键参数的表格化总结:
memory.stat 核心参数解析表
参数分类 参数名 值(字节) 说明 相关引用
基础内存使用 cache393,973,760
文件缓存和 tmpfs/shmem 内存,用于加速文件访问(可回收)
rss301,170,688
进程匿名内存(堆、栈等)占用,反映实际物理内存使用量
swap0
当前 cgroup 使用的交换空间大小,非零表示物理内存不足
内存页管理 active_anon147,456
活跃的匿名内存页(正在使用的堆、栈内存)
inactive_anon302,727,168
非活跃的匿名内存页(可被回收的堆、栈内存)
active_file44,892,160
活跃的文件缓存页(近期被频繁访问的文件数据)
inactive_file348,233,728
非活跃的文件缓存页(长时间未访问的文件数据,优先回收)
内存事件 pgpgin241,505
从磁盘换入内存的页数,高值可能反映频繁 I/O
pgpgout113,977
从内存换出到磁盘的页数
pgmajfault260
需磁盘 I/O 的硬缺页次数,高值可能引发性能问题
层级管理 hierarchical_memory_limit9,223,372,036…
层级化内存限制(当前值为极大数,表示未启用限制)
total_* 系列(如 total_rss)与同名参数一致
包含当前 cgroup 及其子 cgroup 的总统计值(如 total_rss 表示层级内所有进程的匿名内存总和)
其他 rss_huge171,966,464
透明大页(THP)占用量,大页可减少内存管理开销
unevictable0
不可回收的内存(如 mlock 锁定的内存)
单位与换算 :上述值均为 字节(Bytes) ,可通过 1 GB = 1073741824 Bytes 转换为更易读的单位。例如:cache = 393,973,760 Bytes ≈ 376 MBrss = 301,170,688 Bytes ≈ 287 MB
关键场景判断 :内存压力 :若 rss 接近 hierarchical_memory_limit,需警惕 OOM(内存耗尽)风险。缓存优化 :若 inactive_file 较高,可通过 sync; echo 3 > /proc/sys/vm/drop_caches 手动回收缓存。
与 free/vmstat 的关系 :free -m 中的 buff/cache 对应 cache + buff(部分系统可能合并统计)。vmstat 的 si/so 对应 pgpgin/pgpgout 的实时动态变化。
如需进一步分析具体进程的内存行为,可结合 /proc/<PID>/smaps 或工具如 smem。
memory.numa_stat
1 2 3 4 5 6 7 8 9 10 11 12 ┌──[root@liruilongs.github.io]-[/usr/lib/systemd/system] └─$cat /sys/fs/cgroup/memory/user.slice/user-1000.slice/session-1.scope/memory.numa_stat total=169929 N0=169929 file=95978 N0=95978 anon=73951 N0=73951 unevictable=0 N0=0 hierarchical_total=169929 N0=169929 hierarchical_file=95978 N0=95978 hierarchical_anon=73951 N0=73951 hierarchical_unevictable=0 N0=0 ┌──[root@liruilongs.github.io]-[/usr/lib/systemd/system] └─$
以下是对 memory.numa_stat 输出参数的详细解释
参数名 类型 描述 引用来源
total 基础统计项
当前 cgroup 在 NUMA 节点上的总内存占用(单位字节),等于 anon + file + unevictable 之和
file 基础统计项
文件页缓存(File-backed memory)占用量,例如程序文件、共享库等通过文件映射的内存
anon 基础统计项
匿名页(Anonymous pages)和 Swap 缓存的总量,例如堆、栈等动态分配的内存
unevictable 基础统计项
不可回收的内存页(例如被锁定或标记为不可回收的页面)
hierarchical_total 层级统计项
包含所有子 cgroup 的总内存占用(单位字节),统计范围覆盖当前 cgroup 及其子级
hierarchical_file 层级统计项
包含所有子 cgroup 的文件页缓存总量
hierarchical_anon 层级统计项
包含所有子 cgroup 的匿名页和 Swap 缓存总量
hierarchical_unevictable 层级统计项
包含所有子 cgroup 的不可回收内存总量
补充说明:
NUMA 节点标识 :输出中的 N0=169929 表示当前统计值属于 NUMA 节点 0(N0)。在 NUMA 架构中,每个节点的本地内存访问速度更快,跨节点访问会增加延迟。
层级统计的意义 : 带 hierarchical_ 前缀的参数表示当前 cgroup 及其所有子 cgroup 的累积内存使用量。例如,hierarchical_total 是当前 cgroup 和子 cgroup 在所有 NUMA 节点上的内存总量。
应用场景 :通过对比 total 和 hierarchical_total,可判断子 cgroup 的内存分配是否合理。若 unevictable 值较高,可能需排查是否有进程误用内存锁定(如 mlock)。
上面的输出信息中提供的输出中,total=169929 N0=169929 表示该 cgroup 仅在 NUMA 节点 0 上分配了 169,929 字节内存。其中:file=95978),anon=73951),unevictable=0)。
内存事件指标监控 下面为内存事件指标依次来看一下
参数
作用
memory.usage_in_bytes当前物理内存使用量 (包括匿名内存、文件缓存等)。
memory.memsw.usage_in_bytes当前物理内存 + swap 总使用量 。
memory.failcnt记录内存限制触发的失败次数 (超出 memory.limit_in_bytes 的次数)。
memory.events内存事件计数器 (如 oom 溢出次数、under_oom 低内存状态)。
memory.events.local同上,但仅统计当前 cgroup(不包含子 cgroup)。
这里我们使用 tuned 这个服务,这是一个系统调优的服务,作为一个独立的 service unit 存在,所以会有一个单独 Cgroup 分组
1 2 3 4 5 6 7 8 9 10 11 12 ┌──[root@liruilongs.github.io]-[/usr/lib/systemd/system] └─$pgrep tuned 3654 ┌──[root@liruilongs.github.io]-[/usr/lib/systemd/system] └─$ps -o cgroup 3654 CGROUP 11:pids:/system.slice/tuned.service, 8:memory:/system.slice/tuned.service, 2:devices:/system.slice/tuned.service, 1:name=systemd:/system.slice/tuned.service ┌──[root@liruilongs.github.io]-[/usr/lib/systemd/system] └─$
可以在 Cgroup 路径下面看到所有的指标数据 /sys/fs/cgroup/memory/system.slice/tuned.service/,还有部分内核相关的,这里我们只看一下内存相关的
1 2 3 4 5 6 7 8 9 10 11 12 ┌──[root@liruilongs.github.io]-[/usr/lib/systemd/system] └─$cat /sys/fs/cgroup/memory/system.slice/tuned.service/ cgroup.clone_children memory.kmem.limit_in_bytes memory.max_usage_in_bytes memory.pressure_level cgroup.event_control memory.kmem.max_usage_in_bytes memory.memfs_files_info memory.qos_level cgroup.kill memory.kmem.slabinfo memory.memsw.failcnt memory.soft_limit_in_bytes cgroup.procs memory.kmem.tcp.failcnt memory.memsw.limit_in_bytes memory.stat memory.events memory.kmem.tcp.limit_in_bytes memory.memsw.max_usage_in_bytes memory.swappiness memory.events.local memory.kmem.tcp.max_usage_in_bytes memory.memsw.usage_in_bytes memory.usage_in_bytes memory.failcnt memory.kmem.tcp.usage_in_bytes memory.min memory.use_hierarchy memory.force_empty memory.kmem.usage_in_bytes memory.move_charge_at_immigrate notify_on_release memory.high memory.limit_in_bytes memory.numa_stat tasks memory.kmem.failcnt memory.low memory.oom_control
memory.usage_in_bytes : 当前 cgroup 中所有进程实际使用的物理内存总量(包括 RSS 和 Page Cache),单位字节(约 15.86 MB)。
1 2 3 4 ┌──[root@liruilongs.github.io]-[/usr/lib/systemd/system] └─$cat /sys/fs/cgroup/memory/system.slice/tuned.service/memory.usage_in_bytes 16629760
memory.memsw.usage_in_bytes : 当前 cgroup 中所有进程使用的物理内存 + Swap 空间的总量(单位字节)。此处与物理内存相等,说明未使用 Swap。
1 2 3 ┌──[root@liruilongs.github.io]-[/usr/lib/systemd/system] └─$cat /sys/fs/cgroup/memory/system.slice/tuned.service/memory.memsw.usage_in_bytes 16629760
memory.failcnt 存使用达到 memory.limit_in_bytes 设定的限制值的次数。值为 0 表示未触发过内存超限。
1 2 3 ┌──[root@liruilongs.github.io]-[/usr/lib/systemd/system] └─$cat /sys/fs/cgroup/memory/system.slice/tuned.service/memory.failcnt 0
memory.event s 内存事件计数器:
low: 低内存压力事件次数
high: 高内存压力事件次数
limit_in_bytes: 达到内存限制的次数
oom: OOM(内存耗尽)触发次数。全为 0 表示无相关事件发生。
1 2 3 4 5 6 7 8 ┌──[root@liruilongs.github.io]-[/usr/lib/systemd/system] └─$cat /sys/fs/cgroup/memory/system.slice/tuned.service/memory.events low 0 high 0 limit_in_bytes 0 oom 0 ┌──[root@liruilongs.github.io]-[/usr/lib/systemd/system] └─$
当然还有一些其他的参数,感兴小伙伴可以研究下,通过去读上面的参数可以进行性能分析,系统监控
proc 内存伪文件系统 如果需要详细查看一个进程使用了哪些虚拟地址,可用使用 pmap PID 命令或者基于 proc 内存伪文件系统查看内存详细信息,比如 /proc/1/status,/proc/PID/maps 和/proc/PID/smaps等,
查看进程详细内存段数据 pmap 1002
快速查看进程的虚拟内存布局和总占用。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 ┌──[root@liruilongs.github.io]-[~] └─$pmap 1002 1002: /usr/bin/python3 -Es /usr/sbin/tuned -l -P 0000561ae3586000 4K r---- python3.9 0000561ae3587000 4K r-x-- python3.9 0000561ae3588000 4K r---- python3.9 0000561ae3589000 4K r---- python3.9 。。。。。。。。。。。。。。。。 00007ffc6f79b000 132K rw--- [ stack ] 00007ffc6f7ce000 16K r---- [ anon ] 00007ffc6f7d2000 8K r-x-- [ anon ] ffffffffff600000 4K --x-- [ anon ] total 256364K ┌──[root@liruilongs.github.io]-[~] └─$
对应的列分别表示:内存段的起始虚拟地址(如 0000561ae3586000)。内存段的大小(如 4K)。内存访问权限 (r)可读 |(w)可写 |(x)可执行 |(s)共享 |(p)私有
/proc/1/maps
详细列出所有内存段的地址范围、权限和映射文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 ┌──[root@liruilongs.github.io]-[~] └─$cat /proc/1/maps | head -20 55e05a46b000-55e05a471000 r--p 00000000 fd:00 372298 /usr/lib/systemd/systemd 55e05a471000-55e05a47c000 r-xp 00006000 fd:00 372298 /usr/lib/systemd/systemd ............ 55e05a483000-55e05a484000 rw-p 00017000 fd:00 372298 /usr/lib/systemd/systemd 55e05af99000-55e05b2a3000 rw-p 00000000 00:00 0 [heap] 7ff43c000000-7ff43c021000 rw-p 00000000 00:00 0 .................................... 7ff44b762000-7ff44bf62000 rw-p 00000000 00:00 0 7ff44bf62000-7ff44bf63000 ---p 00000000 00:00 0 7ff44bf63000-7ff44c766000 rw-p 00000000 00:00 0 7ff44c766000-7ff44c768000 r--p 00000000 fd:00 33948825 /usr/lib64/libffi.so.8.1.0 7ff44c768000-7ff44c76e000 r-xp 00002000 fd:00 33948825 /usr/lib64/libffi.so.8.1.0 ................................ 7ff44c771000-7ff44c772000 rw-p 0000a000 fd:00 33948825 /usr/lib64/libffi.so.8.1.0
可以看到在上面的基础上,展示了内存段的起始和结束虚拟地址(如 55e05a46b000-55e05a471000)。多了映射文件在文件中的偏移量(十六进制,如 00000000)。文件所在设备的编号(格式 fd:00,主设备号:次设备号)。文件的 inode 编号(如 372298)。
/proc/1/smaps
提供每个内存段的详细物理内存统计(RSS、PSS、共享/私有内存等)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 ┌──[root@liruilongs.github.io]-[~] └─$cat /proc/1/smaps | head -30 55e05a46b000-55e05a471000 r--p 00000000 fd:00 372298 /usr/lib/systemd/systemd Size: 24 kB KernelPageSize: 4 kB MMUPageSize: 4 kB Rss: 24 kB Pss: 7 kB Shared_Clean: 24 kB Shared_Dirty: 0 kB Private_Clean: 0 kB Private_Dirty: 0 kB Referenced: 24 kB Anonymous: 0 kB LazyFree: 0 kB AnonHugePages: 0 kB ShmemPmdMapped: 0 kB FilePmdMapped: 0 kB Shared_Hugetlb: 0 kB Private_Hugetlb: 0 kB Swap: 0 kB SwapPss: 0 kB Locked: 0 kB THPeligible: 0 VmFlags: rd mr mw me sd 55e05a471000-55e05a47c000 r-xp 00006000 fd:00 372298 /usr/lib/systemd/systemd Size: 44 kB KernelPageSize: 4 kB ┌──[root@liruilongs.github.io]-[~] └─$
部分字段说明:
Size: 内存段的虚拟大小(如 24 kB)。
Rss:(Resident Set Size) 实际占用的物理内存(包含共享内存)。
Pss:(Proportional Set Size) 按共享比例计算的物理内存(如 3 个进程共享 24KB → 每个进程 Pss 8KB)。
Shared_Clean/Shared_Dirty: 共享内存中未修改/已修改的部分。
Private_Clean/Private_Dirty: 私有内存中未修改/已修改的部分。
Swap: 被交换到磁盘的内存大小。
VmFlags: 内存段的属性标志(如 rd 可读,mr 可映射,mw 可写等)。
进程全局内存数据统计 status 用于展示当前进程的一些基本指标,进程基础信息,权限与身份,信号与中断等
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 ┌──[root@liruilongs.github.io]-[/usr/lib/systemd/system] └─$cat /proc/1/status Name: systemd Umask: 0000 State: S (sleeping) Tgid: 1 Ngid: 0 Pid: 1 PPid: 0 TracerPid: 0 Uid: 0 0 0 0 Gid: 0 0 0 0 FDSize: 256 Groups: NStgid: 1 NSpid: 1 NSpgid: 1 NSsid: 1 VmPeak: 165112 kB VmSize: 100636 kB VmLck: 0 kB VmPin: 0 kB VmHWM: 12688 kB VmRSS: 12688 kB RssAnon: 4084 kB RssFile: 8604 kB RssShmem: 0 kB VmData: 19052 kB VmStk: 1036 kB VmExe: 884 kB VmLib: 8832 kB VmPTE: 84 kB VmSwap: 0 kB HugetlbPages: 0 kB CoreDumping: 0 THP_enabled: 1 Threads: 1 SigQ: 0/29616 ............................................ NoNewPrivs: 0 Seccomp: 0 Seccomp_filters: 0 Speculation_Store_Bypass: thread vulnerable Cpus_allowed: f Cpus_allowed_list: 0-3 Mems_allowed: 00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000001 Mems_allowed_list: 0 voluntary_ctxt_switches: 2558 nonvoluntary_ctxt_switches: 483
这里只关注内存相关的
虚拟内存核心指标
参数 值 描述 引用来源
VmPeak 165,112 kB
进程生命周期内虚拟内存的 峰值 (含已分配但未使用的内存),反映进程曾达到的最大内存需求
VmSize 100,636 kB
当前进程 虚拟地址空间总大小 (包括代码、数据、堆、栈等所有映射区域),约 98.27 MB
物理内存核心指标
参数 值 描述 引用来源
VmHWM 12,688 kB
进程物理内存使用 峰值 (Resident Set Size 最大值),约 12.38 MB
VmRSS 12,688 kB
当前实际驻留物理内存(RSS),等于 RssAnon + RssFile + RssShmem,约 12.38 MB
RssAnon 4,084 kB
匿名页(动态分配的堆/栈内存)占用的物理内存,例如 malloc 分配的未映射文件的内存
RssFile 8,604 kB
文件页缓存占用的物理内存(如加载的共享库、内存映射文件)
RssShmem 0 kB
共享内存段(如 shmget 创建的 IPC 内存)占用的物理内存
内存区域细分指标
参数 值 描述 引用来源
VmData 19,052 kB
数据段 + 堆 的虚拟内存大小(动态分配的内存通过 brk 或 mmap 扩展)
VmStk 1,036 kB
栈空间 的虚拟内存大小(存放局部变量和函数调用帧),默认上限由 ulimit -s 控制
VmExe 884 kB
可执行代码段 的虚拟内存大小(程序本身的机器指令,只读)
VmLib 8,832 kB
共享库 的虚拟内存大小(如 glibc 等动态链接库)
其他关键参数
参数 值 描述 引用来源
VmLck 0 kB
锁定的物理内存 (通过 mlock 系统调用防止被换出到 Swap),常用于实时性要求高的场景
VmPTE 84 kB
页表项 占用的物理内存(用于管理虚拟地址到物理地址的映射关系)
VmSwap 0 kB
当前已换出到 Swap 分区 的内存大小(若值持续增长,需排查内存泄漏或物理内存不足)
关键应用场景分析
内存泄漏检测
对比 VmSize 和 VmRSS:若 VmSize 持续增长而 VmRSS 稳定,可能为虚拟内存分配过多但未实际使用(如未初始化的 malloc)。
监控 VmSwap:若长期非零,需检查物理内存是否不足或进程存在内存滥用。
性能优化方向
共享库优化 :VmLib 值较高时,可考虑静态链接或减少动态库依赖以降低内存开销。堆栈管理 :VmData 和 VmStk 异常增长可能提示堆内存泄漏或递归调用过深。
系统资源分配
VmHWM 可用于设置 CGroup 内存限制(memory.max_usage_in_bytes),避免单个进程耗尽物理内存。RssFile 较高时,可通过清理缓存(sync; echo 1 > /proc/sys/vm/drop_caches)释放非关键文件缓存。
statm 用于展示进程内存快照,但需注意 单位是内存页,通常 1 页 = 4 KB
1 2 3 ┌──[root@liruilongs.github.io]-[/usr/lib/systemd/system] └─$cat /proc/1/statm 25159 3172 2151 221 0 5022 0
字段解析
参数 值 描述 换算为 KB 引用来源
size 25159
进程虚拟地址空间总大小(含代码、数据、堆栈等所有映射区域)
25159 × 4 ≈ 100,636 KB
Resident 3172
实际驻留物理内存(RSS),即当前进程使用的物理内存总量
3172 × 4 ≈ 12,688 KB
Shared 2151
共享内存页数(如动态链接库、共享内存段等被多个进程共享的部分)
2151 × 4 ≈ 8,604 KB
Trs 221
可执行代码段(Text Resident Set)占用的内存页(如程序自身的机器指令)
221 × 4 ≈ 884 KB
Lrs 0
库的内存页数(Linux 2.6+ 中已废弃,通常为 0)
-
Drs 5022
数据段(堆、全局变量)和用户态栈的总内存页
5022 × 4 ≈ 20,088 KB
dt 0
脏页数量(已修改但未写入磁盘的页,Linux 2.6+ 中已废弃)
-
与 /proc/1/status 的关联 对比 /proc/1/status 中的内存参数可验证数据一致性:VmSize : 100636 kB = size × 4 = 25159 × 4VmRSS : 12688 kB = Resident × 4 = 3172 × 4RssFile : 8604 kB ≈ Shared × 4 = 2151 × 4VmExe : 884 kB = Trs × 4 = 221 × 4VmData + VmStk : 19052 + 1036 = 20088 kB ≈ Drs × 4 = 5022 × 4
smaps_rollup: 读取 smaps_rollup 比遍历 smaps 更高效(减少锁竞争时间),适合高频监控场景,提供进程 全局汇总统计(如总 RSS、PSS、Swap 等)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 ┌──[root@liruilongs.github.io]-[/usr/lib/systemd/system] └─$cat /proc/1/smaps_rollup 56476fafe000-7ffc5b7f8000 ---p 00000000 00:00 0 [rollup] Rss: 12692 kB Pss: 4648 kB Pss_Anon: 3463 kB Pss_File: 1184 kB Pss_Shmem: 0 kB Shared_Clean: 8540 kB Shared_Dirty: 936 kB Private_Clean: 64 kB Private_Dirty: 3152 kB Referenced: 12692 kB Anonymous: 4088 kB LazyFree: 0 kB AnonHugePages: 0 kB ShmemPmdMapped: 0 kB FilePmdMapped: 0 kB Shared_Hugetlb: 0 kB Private_Hugetlb: 0 kB Swap: 0 kB SwapPss: 0 kB Locked: 0 kB
核心内存统计
参数 值 描述 引用来源
Rss 12,692 kB
常驻物理内存总量 (包含共享和私有内存),等于 Shared_Clean + Shared_Dirty + Private_Clean + Private_Dirty
Pss 4,648 kB
比例集内存 (按共享比例分摊后的内存),Pss = Pss_Anon + Pss_File + Pss_Shmem
Pss_Anon 3,463 kB
匿名页(如堆、栈)分摊后的内存,反映独占或部分共享的匿名内存
Pss_File 1,184 kB
文件页缓存(如共享库、映射文件)分摊后的内存
Pss_Shmem 0 kB
共享内存(如 tmpfs)的分摊内存,此处未使用
共享与私有内存分布
参数 值 描述 引用来源
Shared_Clean 8,540 kB
共享的未修改内存(如只读共享库),可被内核直接回收
Shared_Dirty 936 kB
共享的已修改内存(如被多个进程写入的共享内存),需同步到磁盘后才能回收
Private_Clean 64 kB
私有的未修改内存(如未修改的私有数据),可快速回收
Private_Dirty 3,152 kB
私有的已修改内存(如进程堆内存),需写入 Swap 或文件后才能回收
其他关键参数
参数 值 描述 引用来源
Anonymous 4,088 kB
匿名内存总量 (无法关联文件的内存,如 malloc 分配的内存)
Swap 0 kB
已换出到 Swap 分区的内存量,此处为 0 表示未启用 Swap 或内存充足
Locked 0 kB
通过 mlock 锁定的内存(不可被换出),常用于实时性要求高的场景
Referenced 12,692 kB
最近被访问过的内存页,反映当前活跃内存
这是两个 OOM 内存杀手相关的指标,在之后的博客中会和小伙伴分享
1 2 3 4 5 6 ┌──[root@liruilongs.github.io]-[/usr/lib/systemd/system] └─$cat /proc/1/oom_score 0 ┌──[root@liruilongs.github.io]-[/usr/lib/systemd/system] └─$cat /proc/1/oom_score_adj 0
内存的全局监控 内存资源的全局监控一般用于系统级别内存数据实时展示,这里我们也介绍几种方式,关于 通过 BPF 实现全局内存监控会单独拿出来讲。
在学习实际的监控方式之前,我们先来看几个内存相关的术语
交换(物理内存不足) 所有系统RAM芯片的物理内存容量都是固定的。即使应用程序需要的内存容量大于可用的物理内存,Linux内核仍然允许这些程序运行。Linux内核使用硬盘作为临时存储器,这个硬盘空间被称为交换分区(swap space)。
尽管交换是让进程运行的极好的方法,但它却慢的要命。与使用物理内存相比,应用程序使用交换的速度可以慢到一千倍。如果系统性能不佳,确定系统使用了多少交换通常是有用的。
缓冲区(buffer)和缓存(cache)(物理内存太多) 缓存(cache) 相反,如果你的系统物理内存容量超过了应用程序的需求,Linux就会在物理内存中缓存近期使用过的文件,这样,后续访问这些文件时就不用去访问硬盘了。
对要频繁访问硬盘的应用程序来说,这可以显著加速其速度,显然,对经常启动的应用程序而言,这是特别有用的。
应用程序首次启动时,它需要从硬盘读取;但是,如果应用程序留着缓存中,那它就需要从更快速的物理内存读取。
这个硬盘缓存不同于前面章节提到的处理器高速缓存(cache)
缓冲区(buffer) Linux还使用了额外的存储作为缓冲区。为了进一步优化应用程序,Linux为需要被写回硬盘的数据预留了存储空间。这些预留空间被称为缓冲区。如果应用程序要将数据写回硬盘,通常需要花费较长时间,Linux让应用程序立刻继续执行,但将文件数据保存到内存缓冲区。在之后的某个时刻,缓冲区被刷新到硬盘,而应用程序可以立即继续。
高速缓存和缓冲区的使用使得系统内空闲的内存很少,默认情况下,Linux试图尽可能多的使用你的内存。这是好事。
如果Linux侦测到有空闲内存,它就会将应用程序和数据缓存到这些内存以加速未来的访问。由于访问内存的速度比访问硬盘的速度快了几个数量级,因此,这就可以显著地提升整体性能。
如果系统需要缓存空间做更重要的事情,那么缓存空间将被擦除并交给系统。之后,对原来被缓存对象的访问就需要转向硬盘来满足。
活跃与非活跃内存
活跃内存是指当前被进程使用的内存。不活跃内存是指已经被分配了,但暂时还未使用的内存。
这两种类型的内存没有本质上的区别。需要时,Linux找出进程最近最少使用的内存页面,并将它们从活跃列表移动到不活跃列表。当要选择把哪个内存页交换到硬盘时,内核就从不活跃内存列表中进行选择。
传统工具 这里我们介绍了 vmstat/top/free/sar/slabtop 这几种工具
free:快速查看内存总量、使用情况,包括缓冲和缓存,注意available值。top:实时监控系统内存占用及总体使用情况,同时提供内存排序进程。vmstat:查看内存、交换、分页统计,关注si/so判断交换活动。sar:历史数据收集和报告,分析内存趋势,使用sar -r。slabtop:内核slab缓存使用情况,需root权限,检查内核对象内存占用。
vmstat 通过 vmstat 我们可以看到系统级别使用了多少交换分区,物理内存是如何被使用的,以及有多少空闲内存。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 ┌──[root@liruilongs.github.io]-[/usr/lib/systemd/system] └─$vmstat -help Usage: vmstat [options] [delay [count]] Options: -a, --active active/inactive memory -f, --forks number of forks since boot -m, --slabs slabinfo -n, --one-header do not redisplay header -s, --stats event counter statistics -d, --disk disk statistics -D, --disk-sum summarize disk statistics -p, --partition <dev> partition specific statistics -S, --unit <char> define display unit -w, --wide wide output -t, --timestamp show timestamp -h, --help display this help and exit -V, --version output version information and exit For more details see vmstat(8).
这里我们只看 vmstat提供的内存相关统计信息
1 2 3 4 5 ┌──[root@liruilongs.github.io]-[~] └─$ vmstat procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 3 0 0 27270048 3104 984432 0 0 38 23 315 294 4 2 94 0 0
vmstat 调用时没有使用任何命令行选项,它显示的是从 系统启动开始的性能统计数据的均值(si和so),以及其他统计信息的瞬时值(swpd、free、buff和cache)
1 2 3 4 5 6 7 8 ┌──[root@liruilongs.github.io]-[~] └─$ vmstat 1 100 procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 1 0 0 23365320 3104 962048 0 0 176 23 305 296 2 3 95 0 0 1 0 0 23365164 3104 962088 0 0 0 0 768 854 0 0 100 0 0 0 0 0 23364900 3104 962088 0 0 0 0 836 993 0 0 100 0 0 ^C
swpd :当前交换到硬盘的内存总量free :未被操作系统或应用程序使用的物理内存总量buff : 系统缓冲区大小(单位为KB),或用于存放等待保存到硬盘的数据的内存大小(单位为KB)。该存储区允许应用程序向Linux内核发出写调用后立即继续执行(而不是等待直到数据被提交到硬盘)cache :用于保存之前从硬盘读取的数据的系统高速缓存或内存的大小(单位为KB)。如果应用程序再次需要该数据,内核可以从内存而非硬盘抓取数据,由此可提高性能
vmstat显示活跃与非活跃页面的数量信息:vmstat -a
1 2 3 4 5 ┌──[root@liruilongs.github.io]-[~] └─$ vmstat -a procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu----- r b swpd free inact active si so bi bo in cs us sy id wa st 0 0 0 23225336 1987728 6884184 0 0 31 145 267 282 1 1 98 0 0
列
说明(Kb)
active
被使用的活跃内存量。活跃/不活跃的统计数据与缓冲区/高速缓存的是正交的;缓冲区和高速缓存可以是活跃的,也可以是不活跃的
inact
不活跃的内存总量(单位为KB),或一段时间未被使用,适合交换到硬盘的内存量
si
上一次采样中,从硬盘进来的内存交换速率(单位为KB/s)
so
上一次采样中,到硬盘去的内存交换速率(单位为KB/s)
显示内存和交换分区的统计摘要,包括历史累计数据:vmstat -s
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 ┌──[root@liruilongs.github.io]-[~] └─$ vmstat -s 32931532 K total memory 8498760 K used memory 8329368 K active memory 497280 K inactive memory 23470020 K free memory 3104 K buffer memory 959648 K swap cache 10485756 K total swap 0 K used swap 10485756 K free swap 8162 non-nice user cpu ticks 0 nice user cpu ticks 10277 system cpu ticks 220249 idle cpu ticks 653 IO-wait cpu ticks 0 IRQ cpu ticks 435 softirq cpu ticks 0 stolen cpu ticks 682275 pages paged in 83668 pages paged out 0 pages swapped in 0 pages swapped out 907353 interrupts 828939 CPU context switches 1658547198 boot time 9260 forks
这里只看一下不熟悉的指标
列
说明
pages paged in
从硬盘读人系统缓冲区的内存总量(单位为页)
pages paged out
从系统高速缓存写到硬盘的内存总量(单位为页)
pages swapped in
从交换分区读入系统内存的内存总量(单位为页)
pages swapped out
从系统内存写到交换分区的内存总量(单位为页)
used swap
Linux内核目前使用的交换分区容量
free swap
当前可用的交换分区容量
total swap
系统的交换分区总量,即used swap与free swap之和
显示内核 SLAB 缓存信息(内核对象分配的内存):vmstat -m
1 2 3 4 5 6 7 8 9 10 11 12 13 ┌──[root@liruilongs.github.io]-[~] └─$ vmstat -m Cache Num Total Size Pages nf_conntrack_ffff8807fbe22880 153 153 320 51 nf_conntrack_ffff8807f2650000 306 306 320 51 nf_conntrack_ffffffff81ad9d40 306 306 320 51 xfs_dqtrx 0 0 528 62 xfs_icr 0 0 152 53 xfs_inode 37298 37298 960 34 xfs_efd_item 760 800 408 40 ............. ┌──[root@liruilongs.github.io]-[~] └─$
cache:内核缓存名称(如 dentry、inode_cache),表示某一类内核对象(如文件系统、网络协议等)的缓存池。
num/total:当前活跃对象数和总对象数。
size:单个对象占用的内存大小。
Pages: 对应的内存页大小
top(2.x和3.x) 默认情况下,top展示的是对进程的CPU消耗量进行降序排列的列表,但它也可以调整为按内存使用总量排序,以便你能跟踪到哪个进程使用的内存最多。
实验版本
1 2 3 4 5 ┌──[root@liruilongs.github.io]-[~] └─$ top -v procps-ng version 3.3.10 Usage: top -hv | -bcHiOSs -d secs -n max -u|U user -p pid(s) -o field -w [cols]
top运行时切换项
选项
说明
m
该项切换是否将内存使用量信息显示到屏幕
M
按任务使用的内存量排序。由于分配给进程的内存量可能会大于其使用量,因此,该项按驻留集大小排序。驻留集大小是指进程实际使用量,而不是简单的进程请求量
1 2 3 4 5 6 7 8 9 top - 11:48:07 up 14 min, 1 user, load average: 0.07, 0.10, 0.13 Tasks: 273 total, 2 running, 271 sleeping, 0 stopped, 0 zombie %Cpu(s): 0.0 us, 0.0 sy, 0.0 ni,100.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st KiB Mem : 32931532 total, 23319380 free, 8643596 used, 968556 buff/cache KiB Swap: 10485756 total, 10485756 free, 0 used. 23759444 avail Mem PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 889 etcd 20 0 10.559g 29332 11008 S 1.3 0.1 0:10.94 etcd 8089 nginx 20 0 41636 12148 1588 S 1.3 0.0 0:03.35 redis-server
选项
说明
Mem:total,used,free
对物理内存来说,该项表示的是其总量、使用量和空闲量
swap:total,used,free
对交换分区来说,该项表示的是其总量、使用量和空闲量
buff/cache
用于缓冲区写人硬盘的数值和缓存的物理内存总量(单位为KB)
可以建通过 m 键更直观的查看
1 2 3 4 5 6 7 8 9 10 11 12 13 14 top - 11:47:42 up 14 min, 1 user, load average: 0.11, 0.11, 0.13 Tasks: 273 total, 1 running, 272 sleeping, 0 stopped, 0 zombie %Cpu(s): 0.1 us, 0.2 sy, 0.0 ni, 99.6 id, 0.0 wa, 0.0 hi, 0.1 si, 0.0 st KiB Mem : 27.9/32931532 [||||||||||||||||||||| ] KiB Swap: 0.0/10485756 [ ] PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 889 etcd 20 0 10.559g 29332 11008 S 1.0 0.1 0:10.70 etcd 8073 992 20 0 762040 109952 11972 S 1.0 0.3 0:06.59 prometheus 8079 chrony 20 0 860404 575904 9968 S 1.0 1.7 0:30.24 bundle 8082 992 20 0 542292 15620 5476 S 0.3 0.0 0:00.77 node_exporter 8089 nginx 20 0 41636 12148 1588 S 0.3 0.0 0:03.26 redis-server 8093 chrony 20 0 305636 30176 4964 S 0.3 0.1 0:03.33 gitlab-mon 8099 nginx 20 0 398856 11900 3784 S 0.3 0.0 0:00.53 redis_exporter
free free 提供的是系统使用内存的总体情况,包括空闲内存量,这是一个用的最多的查看系统内存的命令
free [-l][·t][-s delay 1[-c count]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 ┌──[root@liruilongs.github.io]-[~] └─$ free -V free from procps-ng 3.3.10 ┌──[root@liruilongs.github.io]-[~] └─$ free --help Usage: free [options] Options: -b, --bytes show output in bytes -k, --kilo show output in kilobytes -m, --mega show output in megabytes -g, --giga show output in gigabytes --tera show output in terabytes --peta show output in petabytes -h, --human show human-readable output --si use powers of 1000 not 1024 -l, --lohi show detailed low and high memory statistics -t, --total show total for RAM + swap -s N, --seconds N repeat printing every N seconds -c N, --count N repeat printing N times , then exit -w, --wide wide output --help display this help and exit -V, --version output version information and exit For more details see free(1).
常用命令
1 2 3 4 5 6 7 8 9 10 ┌──[root@liruilongs.github.io]-[~] └─$ free total used free shared buff/cache available Mem: 32931532 8820980 22388436 27388 1722116 23579356 Swap: 10485756 0 10485756 ┌──[root@liruilongs.github.io]-[~] └─$ free -h total used free shared buff/cache available Mem: 31G 8.4G 21G 26M 1.6G 22G Swap: 9G 0B 9G
统计信息
说明
Total
物理内存与交换空间的总量
Used
使用的物理内存和交换分区的容量
Free
未使用的物理内存和交换分区的容量
shared
进程共享内存使用量,该项已过时,应忽略
Buffers
用作硬盘写缓冲区的物理内存的容量
Cached
用作硬盘读缓存的物理内存的容量
High
高端内存或不能被内核直接访问的内存总量
Low
低端内存或能被内核直接访问的内存总量
Totals
对Total、Used和Free列,该项显示的是该列中物理内存和交换分区的总和
|available |列表示系统当前可被应用程序实际使用的内存量 available ≈ free + buffers + cache(可回收部分)|
-l向你展示使用了多少高端内存和多少低端内存
1 2 3 4 5 6 7 ┌──[root@liruilongs.github.io]-[~] └─$ free -l total used free shared buff/cache available Mem: 32931532 4835004 24441680 35596 3654848 27657976 Low: 32931532 8489852 24441680 High: 0 0 0 Swap: 10485756 0 10485756
-t命令可以查看内存的统计信息
1 2 3 4 5 6 ┌──[root@liruilongs.github.io]-[~] └─$ free -t total used free shared buff/cache available Mem: 32931532 5005552 24808440 35588 3117540 27487560 Swap: 10485756 0 10485756 Total: 43417288 5005552 35294196
选项说明
-s delay:使free按每delay秒的间隔输出新的内存统计数据-c count:使free 输出count次新的统计数据
1 2 3 4 5 6 7 8 9 10 11 ┌──[root@liruilongs.github.io]-[~] └─$ free -s 2 -c 2 total used free shared buff/cache available Mem: 32931532 5405500 24408372 35588 3117660 27087612 Swap: 10485756 0 10485756 total used free shared buff/cache available Mem: 32931532 5405460 24408388 35588 3117684 27087652 Swap: 10485756 0 10485756 ┌──[root@liruilongs.github.io]-[~] └─$
slabtop slabtop实时显示内核是如何分配其各种缓存的,以及这些缓存的被占用情况。在内部,内核有一系列的缓存,它们由一个或多个分片(slab)构成。每个分片包括一组对象,对象个数为一个或多个。
这些对象可以是活跃的(使用的)或非活跃的(未使用的)。slabtop向你展示的是不同分片的状况。它显示了这些分片的被占用情况,以及它们使用了多少内存。
slabtop可以一窥Linux内核的数据结构。每一种分片类型都与Linux内核紧密相关。如果某个特定分片使用了大量的内核内存,那么阅读Linux内核源代码和搜索互联网是找出这些分片用在哪里的最好的两种方法。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 ┌──[root@liruilongs.github.io]-[~] └─$ slabtop --help Usage: slabtop [options] Options: -d, --delay <secs> delay updates -o, --once only display once, then exit -s, --sort <char> specify sort criteria by character (see below) -h, --help display this help and exit -V, --version output version information and exit The following are valid sort criteria: a: sort by number of active objects b: sort by objects per slab c: sort by cache size l: sort by number of slabs v: sort by number of active slabs n: sort by name o: sort by number of objects (the default) p: sort by pages per slab s: sort by object size u: sort by cache utilization For more details see slabtop(1).
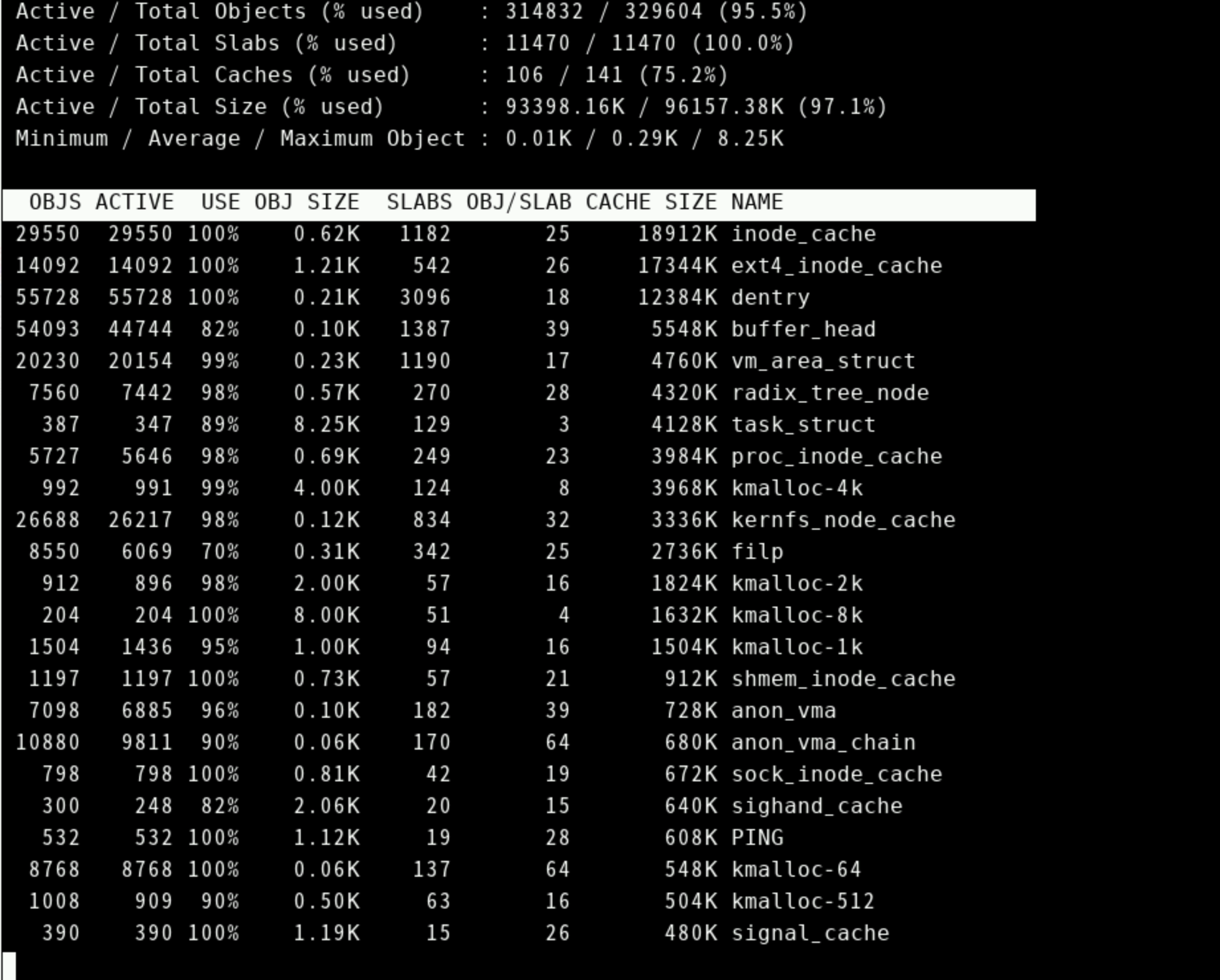
实时监控 Linux 内核 SLAB 缓存,间隔2s,对缓存进行排序
1 2 3 4 5 6 7 8 9 10 11 12 ┌──[root@liruilongs.github.io]-[~] └─$ slabtop -d 2 -s c Active / Total Objects (% used) : 2172003 / 2195023 (99.0%) Active / Total Slabs (% used) : 49649 / 49649 (100.0%) Active / Total Caches (% used) : 69 / 95 (72.6%) Active / Total Size (% used) : 466189.06K / 477588.18K (97.6%) Minimum / Average / Maximum Object : 0.01K / 0.22K / 8.00K OBJS ACTIVE USE OBJ SIZE SLABS OBJ/SLAB CACHE SIZE NAME 727440 727339 99% 0.19K 17320 42 138560K dentry 571038 570600 99% 0.10K 14642 39 58568K buffer_head 305088 304062 99% 0.06K 4767 64 19068K kmalloc-64
我们来看一下输出
汇总信息(全局统计)
字段
含义
当前值
说明
Active / (% used) 活跃对象与总对象数的比例
2172003 / 2195023 (99.0%)系统中 99% 的缓存对象 ,表明内核缓存高度活跃。
Active / Total Slabs (% used) 活跃 Slab 与总 Slab 的比例
49649 / 49649 (100.0%)所有 Slab 均被完全占用 ,无空闲内存块,可能因内存需求高或分配策略严格。
Active / Total Caches (% used) 活跃缓存与总缓存的比例
69 / 95 (72.6%)系统中.6% 的缓存正在被使用**,剩余缓存可能为低优先级或未初始化。
Active / Total Size (% used) 活跃内存与总内存的比例
466189.06K / 477588.18K (97.6%)总缓存内存约 466MB ,占分配内存的 97.6%,内存利用率极高。
Minimum / Average / Maximum Object 对象大小范围
0.01K / 0.22K / 8.00K内核缓存对象大小跨度大,平均 0.22KB(224字节) ,以小型对象为主。|
详细缓存列表(按缓存大小排序)
字段
说明
dentry 行示例buffer_head 行示例kmalloc-64 行示例
OBJS 缓存中总对象数
727440571038305088
ACTIVE 当前活跃对象数
727339570600304062
USE 活跃对象占比
99%99%99%
OBJ SIZE 单个对象大小
0.19K(约 194字节)0.10K(约 102字节)0.06K(约 61字节)
SLABS Slab 数量
17320146424767
OBJ/SLAB 每个 Slab 包含的对象数
423964
CACHE SIZE 该缓存占用的总内存
138560K(约 135MB)58568K(约 57MB)19068K(约 18.6MB)
NAME 缓存名称
dentry(目录项缓存)buffer_head(块设备 I/O 缓存)kmalloc-64(内核动态分配的 64字节内存块)
通过 slabtop 的输出,可快速定位内核内存的热点缓存,结合具体场景优化系统性能或排查内存泄漏问题。
sar 上面讲的系统内存监控工具都是实时工具,有时候可能当尝试去解决问题的时候,问题已经发生完成了,即错过了解决问题的最佳时机,所以我们需要查看历史监控数据,所以就有了 sar
sar [-B][-rl[-R]
选项
描述
-B
报告的信息为内核与磁盘之间交换的块数。此外,对v2.5之后的内核版本,该项报告的信息为缺页数量
-W
报告的是系统交换的页数
-r
报告系统使用的内存信息。它包括总的空闲内存、正在使用的交换分区、缓存和缓冲区的信息
交换分区活动监控
1 2 3 4 5 6 7 8 9 10 11 12 ┌──[root@liruilongs.github.io]-[~] └─$ sar -W Linux 3.10.0-693.el7.x86_64 (liruilongs.github.io) 2022年07月23日 _x86_64_ (6 CPU) 11时33分39秒 LINUX RESTART 11时40分01秒 pswpin/s pswpout/s 11时50分01秒 0.00 0.00 12时00分01秒 0.00 0.00 12时10分01秒 0.00 0.00 12时20分01秒 0.00 0.00 平均时间: 0.00 0.00
所有时间点的值均为 0.00,表明系统在监控期间 未发生 Swap 交换活动。物理内存充足,未触发内存回收机制,系统未因内存不足使用 Swap
pswpin/s:每秒从 Swap 分区换入到物理内存的页面数量。
pswpout/s:每秒从物理内存换出到 Swap 分区的页面数量。
内存分页与缺页统计
1 2 3 4 5 6 7 8 9 10 11 12 13 14 ┌──[root@liruilongs.github.io]-[~] └─$ sar -B Linux 3.10.0-693.el7.x86_64 (liruilongs.github.io) 2022年07月23日 _x86_64_ (6 CPU) 11时33分39秒 LINUX RESTART 11时40分01秒 pgpgin/s pgpgout/s fault/s majflt/s pgfree/s pgscank/s pgscand/s pgsteal/s %vmeff 11时50分01秒 12.52 125.74 677.40 0.02 692.72 0.00 0.00 0.00 0.00 12时00分01秒 138.94 533.55 1253.45 0.17 1110.67 0.00 0.00 0.00 0.00 12时10分01秒 118.52 5527.63 35379.48 0.20 19923.40 0.00 0.00 0.00 0.00 12时20分01秒 15.85 122.99 3750.36 0.02 1989.95 0.00 0.00 0.00 0.00 平均时间: 71.46 1578.02 10268.63 0.10 5931.11 0.00 0.00 0.00 0.00 ┌──[root@liruilongs.github.io]-[~] └─$
pgpgin/s:每秒从磁盘读入内存的页数(单位:页/秒)。pgpgout/s:每秒从内存写入磁盘的页数(单位:页/秒)。fault/s:每秒发生的缺页中断次数(包括次缺页和主缺页)。majflt/s:每秒发生的主缺页次数(需从磁盘加载数据)。pgfree/s:每秒释放到空闲列表的内存页数。
pgpgout/s 较高(平均 1578.02):系统存在频繁的页写入磁盘操作,可能与缓存刷新或应用程序的磁盘写入有关。majflt/s 极低(0.10):主缺页较少,表明大部分缺页通过缓存(次缺解决,内存压力较小,关于缺页,会在之后的文章中和小伙伴分享
内存使用统计
显示系统的物理内存和交换空间使用情况
1 2 3 4 5 6 7 8 9 ┌──[root@liruilongs.github.io]-[~] └─$ sar -r 1 3 Linux 3.10.0-693.el7.x86_64 (liruilongs.github.io) 2022年07月23日 _x86_64_ (6 CPU) 12时39分27秒 kbmemfree kbmemused %memused kbbuffers kbcached kbcommit %commit kbactive kbinact kbdirty 12时39分28秒 23253572 9677960 29.39 3104 2789588 5138464 11.84 6864288 1980388 96 12时39分29秒 23253572 9677960 29.39 3104 2789620 5138464 11.84 6864300 1980416 96 12时39分30秒 23253572 9677960 29.39 3104 2789620 5138464 11.84 6864300 1980416 96 平均时间: 23253572 9677960 29.39 3104 2789609 5138464 11.84 6864296 1980407 96
kbmemfree:空闲物理内存(约 22.25GB)。kbmemused:已用物理内存(约 9.24GB)。%memused:内存使用率(29.39%)。kbbuffers:内核缓冲区占用的内存(3.03MB)。kbcached:文件系统缓存占用的内存(约 2.66GB)。
内存页的动态分配速率 ,包括释放、缓冲和缓存的页面变化。
1 2 3 4 5 6 7 8 9 10 11 12 ┌──[root@liruilongs.github.io]-[~] └─$ sar -R 1 3 Linux 3.10.0-693.el7.x86_64 (liruilongs.github.io) 2022年07月23日 _x86_64_ (6 CPU) 12时39分44秒 frmpg/s bufpg/s campg/s 12时39分45秒 -96.00 0.00 6.00 12时39分46秒 29.00 0.00 0.00 12时39分47秒 -33.00 0.00 0.00 平均时间: -33.33 0.00 2.00 ┌──[root@liruilongs.github.io]-[~] └─$
frmpg/s:每秒释放到空闲列表的页面数(负值表示释放)。
bufpg/s:每秒分配给缓冲区的页面数。
campg/s:每秒分配给缓存的页面数。
Cgroup 方式 systemd-cgtop 通过 systemd-cgtop --order=memory,可以展示各个控制组(Control Group)按内存使用情况的排序信息。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 ┌──[root@liruilongs.github.io]-[/usr/lib/systemd/system] └─$systemd -cgtop --order=memory Control Group Tasks %CPU Memory Input/s Output/s / 320 - 1.4G - - user.slice 143 - 767.2M - - user.slice/user-1000.slice 115 - 695.2M - - user.slice/user-1000.slice/session-1.scope 84 - 674.1M - - system.slice 101 - 500.9M - - system.slice/hostguard.service 33 - 136.1M - - user.slice/user-986.slice 28 - 72.0M - - ...................... - system.slice/auditd.service 2 - 3.6M - - system.slice/accounts-daemon.service 3 - 2.8M - - system.slice/rpcbind.service 1 - 2.4M - - system.slice/rtkit-daemon.service 3 - 2.3M - - system.slice/gssproxy.service 6 - 2.0M - - system.slice/sshd.service 1 - 2.0M - -
最上方的“/”表示根控制组,其下有多个子控制组,如user.slice等。每个控制组包含任务(Tasks)数量、CPU使用率(%CPU)、内存(Memory)使用量、输入输出速率(Input/s和Output/s)等信息。
同时可以看到不同用户会话(如user-1000.slice,user-986.slice)、系统服务(如hostguard.service、lightdm.service等)的内存使用情况。通过这些信息能快速了解系统中各部分的内存占用状况,有助于发现内存使用异常的控制组,进而进行内存相关的调优或故障排查。
proc 内存伪文件系统 /proc/meminfo Linux内核提供用户可读文本文件/proc/meminfo来显示当前系统范围内的内存性能统计信息,
它提供了系统范围内内存统计数据的超集,包括了vmstat、top、free和procinfo的信息,但是使用起来有一定的难度。如果你想定期更新,就需要自己写一个脚本或一些代码来实现这个功能。如果你想保存内存性能信息或是将其与CPU统计信息相协调,就必须创建一个新的工具或是写一个脚本。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 ┌──[root@liruilongs.github.io]-[~] └─$ cat /proc/meminfo MemTotal: 32931532 kB MemFree: 23182352 kB MemAvailable: 25878308 kB Buffers: 3104 kB Cached: 2790760 kB SwapCached: 0 kB Active: 6933748 kB Inactive: 1981384 kB Active(anon): 6124200 kB Inactive(anon): 32624 kB Active(file): 809548 kB Inactive(file): 1948760 kB Unevictable: 0 kB Mlocked: 0 kB SwapTotal: 10485756 kB SwapFree: 10485756 kB Dirty: 84 kB Writeback: 0 kB AnonPages: 6121244 kB Mapped: 188304 kB Shmem: 35556 kB Slab: 481624 kB SReclaimable: 340480 kB SUnreclaim: 141144 kB KernelStack: 12944 kB PageTables: 31076 kB NFS_Unstable: 0 kB Bounce: 0 kB WritebackTmp: 0 kB CommitLimit: 26951520 kB Committed_AS: 5158652 kB VmallocTotal: 34359738367 kB VmallocUsed: 225072 kB VmallocChunk: 34359310332 kB HardwareCorrupted: 0 kB AnonHugePages: 5437440 kB HugePages_Total: 0 HugePages_Free: 0 HugePages_Rsvd: 0 HugePages_Surp: 0 Hugepagesize: 2048 kB DirectMap4k: 161600 kB DirectMap2M: 7178240 kB DirectMap1G: 28311552 kB
部分参数描述
SwapTotal:可用的总交换空间
SwapFree:剩余可用交换空间
Dirty:等待写回磁盘的内存
Writeback:正在主动写回磁盘的内存
AnonPages:映射到用户空间页表的非文件支持页
Mapped:已映射的文件,例如库
Slab:内核数据结构缓存
PageTables:专用于最低级别页表的内存量。如果很多进程连接到同一个共享内存段,这可能会增加到一个很高的值。
NFS_Unstable:NFS 页面发送到服务器,但尚未提交到存储
Bounce:用于块设备的内存bounce buffers
CommitLimit:根据过量使用率 ( vm.overcommit_ratio),这是系统上当前可分配的内存总量。仅当启用了严格的过量使用记帐(模式 2 in )时才遵守此限制vm.overcommit_memory。
Committed_AS:当前在系统上分配的内存量。提交的内存是进程分配的所有内存的总和,即使它还没有被它们“使用”。
VmallocTotal:vmalloc 内存区域的总大小
VmallocUsed:使用的vmalloc区域的数量
VmallocChunk:vmalloc 区域的最大连续块,它是空闲的
HugePages_Total:内核分配的大页数(用 定义vm.nr_hugepages)
HugePages_Free:进程未分配的大页数
HugePages_Rsvd:已承诺从池中分配但尚未分配的大页数。
Hugepagesize:a 的大小hugepage(在基于 Intel 的系统上通常为 2MB)
/proc/slabinfo 前面 slabtop 的数据源,slabinfo 是 Linux 内核提供的用于监控和管理 Slab 内存分配器的关键接口文件,记录了系统中所有活跃的 Slab 缓存信息
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 ┌──[root@liruilongs.github.io]-[~] └─$ cat /proc/slabinfo slabinfo - version: 2.1 nf_conntrack_ffff8807fbe22880 153 153 320 51 4 : tunables 0 0 0 : slabdata 3 3 0 nf_conntrack_ffff8807f2650000 306 306 320 51 4 : tunables 0 0 0 : slabdata 6 6 0 nf_conntrack_ffffffff81ad9d40 306 306 320 51 4 : tunables 0 0 0 : slabdata 6 6 0 xfs_dqtrx 0 0 528 62 8 : tunables 0 0 0 : slabdata 0 0 0 xfs_icr 0 0 152 53 2 : tunables 0 0 0 : slabdata 0 0 0 xfs_inode 37298 37298 960 34 8 : tunables 0 0 0 : slabdata 1097 1097 0 xfs_efd_item 760 800 408 40 4 : tunables 0 0 0 : slabdata 20 20 0 xfs_buf_item 408 408 240 68 4 : tunables 0 0 0 : slabdata 6 6 0 xfs_btree_cur 234 234 208 39 2 : tunables 0 0 0 : slabdata 6 6 0 xfs_log_ticket 352 352 184 44 2 : tunables 0 0 0 : slabdata 8 8 0 bio-1 408 408 320 51 4 : tunables 0 0 0 : slabdata 8 8 0 ip6_dst_cache 252 252 448 36 4 : tunables 0 0 0 : slabdata 7 7 0 RAWv6 624 624 1216 26 8 : tunables 0 0 0 : slabdata 24 24 0 ...........
name:缓存名称,通常与内核对象类型相关 xfs_inode 表示 XFS 文件系统的 inode 缓存)。active_objs:当前活跃(已分配)的对象数量。num_objs:缓存中总对象数量(包括空闲和活跃)。objsize:单个对象的大小(单位:字节)。objperslab:每个 Slab(内存块)包含的对象数量。pagesperslab:每个 Slab 占用的物理页数(1 页通常为 4KB)
可以看到有我们在上面通过 slabtop 命令看到的一些缓存对象
xfs_inode:XFS 文件系统的 inode 缓存nf_conntrack_:网络连接跟踪缓存(用于防火墙/NAT)
利用BPF 观测 Linux 内存情况
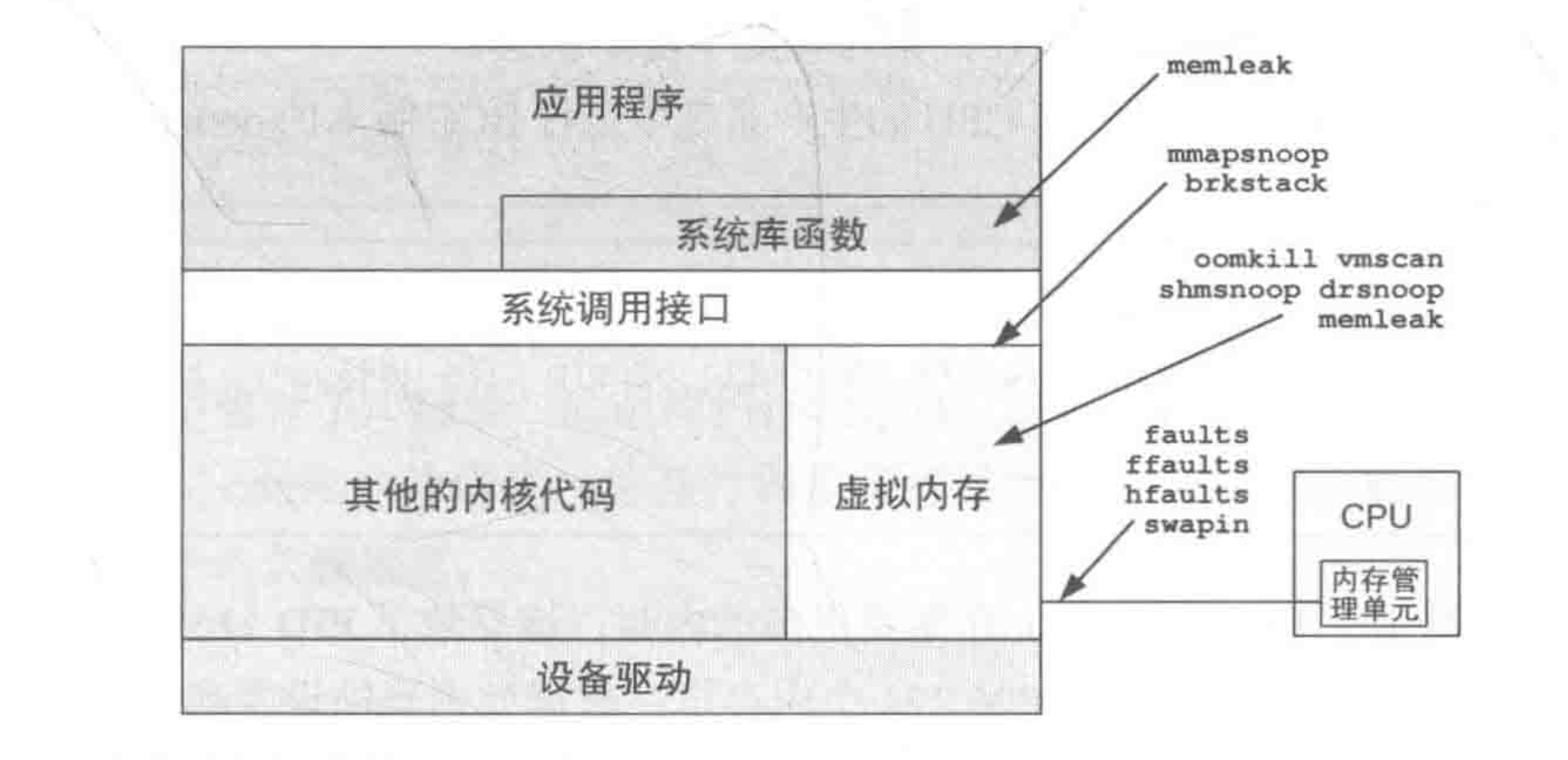
BPF 跟踪工具可以给各种内存行为提供更多的信息,可以用 BPF 跟踪软件事件及系统调用和缺页错误相关的跟踪点来分析;还可以使用 kprobes 跟踪内核中内存分配的函数;或使用 uprobes 来跟踪库函数、应用程序运行时,以及应用程序自带的内存分配器;或使用 USDT 探针来跟踪 libc 内存分配器事件;以及使用 PMC对内存访问进行溢出采样。
这里我们简单看看下上面提到的几个BPF关键名词:
动态跟踪点: kprobes 和 uprobes,类似于内核态和用户态的方法埋点,比较灵活,可以任意监控
kprobes: 通过在内核函数入口或指定指令位置插入断点指令(如 x86 的 int3),动态注入回调函数。当内核执行到探测点时,触发回调函数并记录上下文信息(如寄存器状态、参数等)。例如,可监控 kmalloc、kfree 等内核内存管理函数的行为。uprobes: 通过修改用户程序的 ELF 文件指令,在库函数(如 malloc)或应用程序的自定义内存分配器处插入探测点。其原理类似于 kprobes,但作用于用户态进程。
静态跟踪点:USDT 探针,用户态会将稳定的事件名字编码到软件代码中,监控点都是编译的时候写死的
USDT :探针在程序编译阶段通过宏定义(如 dtrace_probe、stap_probe)插入代码中,形成固定的观测点位。
PMC(Performance Monitoring Counters): 通过 CPU 硬件计数器统计内存访问事件(如缓存未命中、TLB 失效等),支持溢出采样模式。当事件计数达到阈值时触发中断,记录调用栈信息
BPF 可以跟踪各种内存事件,包括内存分配、内存映射、缺页错误、换页操作等:在跟踪这些事件的大部分情况下都可以抓取对应的调用栈信息,以便理解事件发生的原因。
常见的内存活动 事件源
事件类型
事件源
用户态内存分配
使用 uprobes 跟踪内存分配器函数,使用 USDT probes 跟踪 libc
内核态内存分配
使用 kprobes 跟踪内存分配器函数,以及 kmem 跟踪点
堆内存扩展
brk 系统调用跟踪点
共享内存函数
系统调用跟踪点
缺页错误
kprobes、软件事件,以及 exception 跟踪点
页迁移
migration 跟踪点
页压缩
compaction 跟踪点
VM 扫描器
vmscan 跟踪点
内存访问周期
PMC
需要说明: 使用 BPF 的方式,每秒调用事件几百万次仍会累积成不小的开销。根据所跟踪事件的发生频率不同,以及对应的 BPF 程序,运行时仍有可能造成 10%左右的性能损耗。在极端情况下甚至可能将软件运行速度降至原先的 1/10。缺页错误,页换出,brk()调用, mmap() 调用等,跟踪这些事件基本开销基本可以忽略不计。
内存溢出(OOM Kil)事件发生时系统状态如何? oomkill(8) 是一个 BCC 和 bpftrace 工具,用来跟踪内核的 OOM Killer 事件的信息,以及打印出平均负载等详细信息。
OOM Killer 事件: OOM Killer(Out-Of-Memory Killer)是内核在系统内存严重不足时触发的紧急机制,通过终止进程释放内存以维持系统稳定
通过BPF 和 bpftrace oomkill 工具,我们可以在触发 OOM killer 事件之后,观察到系统平均负载等一些其他的信息
平均负载信息可以在 OOM 发生时提供整个系统状态的一些 上下文信息,展示出系统整体是正在变忙还是处于稳定状态,以及那个进程触发了 OOM Killer 和,被 OOM Killer 杀掉的进程是那个等数据。
我们做一个简单测试,这里需要把交换分区禁用掉,要不换页进程(kswapd)疯狂的输出,不太容易触发 OOM Killer
1 [root@liruilongs.github.io ~]
stress-ng 对 Linux 系统内存施加高压负载
1 2 3 4 5 [root@liruilongs.github.io ~] stress-ng: info: [37336] setting to a 60 second run per stressor stress-ng: info: [37336] dispatching hogs: 4 vm ^[c^Cstress-ng: info: [37336] successful run completed in 40.87s [root@liruilongs.github.io ~]
通过 free 命令观察内存使用情况,中间的那一次输出可以直观的看到内存使用情况
1 2 3 4 5 6 7 8 9 10 11 12 13 [root@liruilongs.github.io ~] total used free shared buff/cache available Mem: 6.5Gi 815Mi 5.6Gi 37Mi 293Mi 5.7Gi Swap: 0B 0B 0B total used free shared buff/cache available Mem: 6.5Gi 6.4Gi 183Mi 39Mi 113Mi 139Mi Swap: 0B 0B 0B total used free shared buff/cache available Mem: 6.5Gi 4.5Gi 2.0Gi 39Mi 84Mi 2.0Gi Swap: 0B 0B 0B [root@liruilongs.github.io ~]
通过 oomkill 工具观察 OOM Killer 情况
可以看到触发的进程主要是 stress-ng(内存压力测试工具)持续申请内存,导致系统物理内存耗尽。部分系统进程(如 oeaware、Xvnc)也触发 OOM,说明内存竞争激烈,系统整体处于高压状态。通过负载指标:loadavg 值较高(如 4.59),表明 CPU 资源负载在升高 。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 [root@liruilongs.github.io ~] Tracing OOM kills... Ctrl-C to stop. 15:41:14 Triggered by PID 1039 ("oeaware" ), OOM kill of PID 39693 ("stress-ng" ), 1704429 pages, loadavg: 4.34 2.87 1.77 6/396 39695 15:41:15 Triggered by PID 39692 ("stress-ng" ), OOM kill of PID 39692 ("stress-ng" ), 1704429 pages, loadavg: 4.34 2.87 1.77 5/396 39696 15:41:16 Triggered by PID 39696 ("stress-ng" ), OOM kill of PID 39694 ("stress-ng" ), 1704429 pages, loadavg: 4.31 2.89 1.78 5/396 39697 15:41:17 Triggered by PID 39698 ("stress-ng" ), OOM kill of PID 39695 ("stress-ng" ), 1704429 pages, loadavg: 4.31 2.89 1.78 5/396 39699 15:41:19 Triggered by PID 1039 ("oeaware" ), OOM kill of PID 39696 ("stress-ng" ), 1704429 pages, loadavg: 4.31 2.89 1.78 5/396 39700 15:41:20 Triggered by PID 2121 ("ibus-ui-gtk3" ), OOM kill of PID 39697 ("stress-ng" ), 1704429 pages, loadavg: 4.31 2.89 1.78 6/396 39701 15:41:22 Triggered by PID 39699 ("stress-ng" ), OOM kill of PID 39698 ("stress-ng" ), 1704429 pages, loadavg: 4.29 2.91 1.80 5/396 39701 15:41:23 Triggered by PID 39700 ("stress-ng" ), OOM kill of PID 39700 ("stress-ng" ), 1704429 pages, loadavg: 4.29 2.91 1.80 6/396 39702 15:41:24 Triggered by PID 39701 ("stress-ng" ), OOM kill of PID 39699 ("stress-ng" ), 1704429 pages, loadavg: 4.29 2.91 1.80 5/396 39704 15:41:25 Triggered by PID 39702 ("stress-ng" ), OOM kill of PID 39701 ("stress-ng" ), 1704429 pages, loadavg: 4.29 2.91 1.80 5/396 39704 15:41:26 Triggered by PID 39703 ("stress-ng" ), OOM kill of PID 39702 ("stress-ng" ), 1704429 pages, loadavg: 4.59 3.00 1.83 5/396 39705 15:41:27 Triggered by PID 39705 ("stress-ng" ), OOM kill of PID 39703 ("stress-ng" ), 1704429 pages, loadavg: 4.59 3.00 1.83 5/396 39706 15:41:29 Triggered by PID 1304 ("Xvnc" ), OOM kill of PID 39704 ("stress-ng" ), 1704429 pages, loadavg: 4.59 3.00 1.83 6/396 39708 15:41:30 Triggered by PID 1492 ("lightdm-gtk-gre" ), OOM kill of PID 39705 ("stress-ng" ), 1704429 pages, loadavg: 4.59 3.00 1.83 5/395 39708 15:41:31 Triggered by PID 39709 ("stress-ng" ), OOM kill of PID 39706 ("stress-ng" ), 1704429 pages, loadavg: 4.94 3.10 1.87 8/395 39710
看下一下数据信息,已第一条日志为例
1 15:41:14 Triggered by PID 1039 ("oeaware" ), OOM kill of PID 39693 ("stress-ng" ), 1704429 pages, loadavg: 4.34 2.87 1.77 6/396 39695。
字段
含义
Triggered by PID触发 OOM 的进程 PID(如内存申请者)
OOM kill of PID被 OOM Killer 终止的进程 PID
1704429 pages被终止进程占用的物理内存页数(1页=4KB,换算为 6.8GB)
loadavg系统负载(1分钟/5分钟/15分钟平均负载)
6/396当前可运行进程数/总进程数
39695最后被创建的进程 PID
下面我们看看上面的功能是如何实现的
bpftrace 对应的工具
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 [root@liruilongs.github.io ~] /* * oomkill Trace OOM killer. * For Linux, uses bpftrace and eBPF. * ...................... * USAGE: oomkill.bt * * Copyright 2018 Netflix, Inc. * Licensed under the Apache License, Version 2.0 (the "License" ) * * 07-Sep-2018 Brendan Gregg Created this. */ BEGIN { printf ("Tracing oom_kill_process()... Hit Ctrl-C to end.\n" ); } kprobe:oom_kill_process { $oc = (struct oom_control *)arg0; time("%H:%M:%S " ); printf ("Triggered by PID %d (\"%s\"), " , pid, comm); printf ("OOM kill of PID %d (\"%s\"), %d pages, loadavg: " , $oc ->chosen->pid, $oc ->chosen->comm, $oc ->totalpages); cat("/proc/loadavg" ); } [root@liruilongs.github.io ~]
通过动态插桩内核函数 oom_kill_process(),捕获 OOM Killer 触发事件
是否有分配一段时间后还是没有释放的内存? 有分配一段时间后还是没有释放的内存,这意味着可能是泄漏的内存。
memleak(8)’是一个 BCC 工具,可以用来跟踪内存分配和释放事件对应的调用栈信息。随着时间的推移,这个工具可以显示长期不被释放的内存。
源码地址:
https://github.com/iovisor/bcc/blob/master/tools/memleak.py
帮助文档:
https://github.com/iovisor/bcc/blob/master/tools/memleak_example.txt
看一个 Demo
1 2 3 4 5 6 7 ┌──[root@liruilongs.github.io]-[~] └─$vim memory_leak_demo.c ┌──[root@liruilongs.github.io]-[~] └─$vim memory_leak_demo.c ┌──[root@liruilongs.github.io]-[~] └─$gcc -g memory_leak_demo.c -o leak_demo
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 ┌──[root@liruilongs.github.io]-[~] └─$cat memory_leak_demo.c #include <stdio.h> #include <stdlib.h> #include <unistd.h> #include <time.h> static int allocation_count = 0 ;void * allocate_memory (size_t size) void *ptr = malloc (size); if (ptr) { allocation_count++; time_t now = time(NULL ); struct tm *tm_info = char time_buf[20 ]; strftime(time_buf, 20 , "%Y-%m-%d %H:%M:%S" , tm_info); printf ("[%s] 分配 #%d: %zu 字节 at 地址 %p\n" , time_buf, allocation_count, size, ptr); } else { perror("内存分配失败" ); } return ptr; } void memory_leak_demo () int *data_buffer = NULL ; for (int i = 0 ; i < 1000 ; i++) { data_buffer = (int *)allocate_memory(1024 * 1024 ); if (data_buffer) { data_buffer[0 ] = i; printf ("写入值: %d\n" , data_buffer[0 ]); } sleep(1 ); } } int main () printf ("===== 内存泄漏演示开始 =====\n" ); memory_leak_demo(); printf ("===== 演示结束(已泄漏 %d 块内存)=====\n" , allocation_count); return 0 ; }
使用 memleak 观测内存问题,下面的输出显示
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 ┌──[root@liruilongs.github.io]-[/usr/share/bcc/tools] └─$./memleak -p $(pgrep leak_demo) --top 3 -s 3 -a 10 -o 20000 Attaching to pid 16369, Ctrl+C to quit. [10:43:05] Top 3 stacks with outstanding allocations: addr = 7fb86c2b7010 size = 15 addr = 7fb86ada2000 size = 1048576 addr = 7fb86b3a8000 size = 1048576 ............................. addr = 7fb86baaf010 size = 1052672 addr = 7fb86b0a5000 size = 1052672 3153935 bytes in 4 allocations from stack 0x00000000004011ae allocate_memory+0x18 [leak_demo] 0x000000000040125f memory_leak_demo+0x23 [leak_demo] 0x00000000004012bd main+0x18 [leak_demo] 0x00007fb870c29590 __libc_start_call_main+0x80 [libc.so.6] 9457664 bytes in 9 allocations from stack 0x00007fb870c980dd sysmalloc+0x7ed [libc.so.6] [10:43:18] Top 3 stacks with outstanding allocations: addr = 7fb86c2b7010 size = 15 .................................... 0x00007fb870c980dd sysmalloc+0x7ed [libc.so.6] [10:43:28] Top 3 stacks with outstanding allocations: addr = 7fb86c2b7010 size = 15 addr = 7fb86ada2000 size = 1048576 addr = 7fb86b3a8000 size = 1048576 ........................... addr = 7fb86b9ae010 size = 1052672 addr = 7fb86baaf010 size = 1052672 addr = 7fb86b0a5000 size = 1052672 addr = 7fb869a8f000 size = 1052672 addr = 7fb86a297000 size = 1052672 3153935 bytes in 4 allocations from stack 0x00000000004011ae allocate_memory+0x18 [leak_demo] 0x000000000040125f memory_leak_demo+0x23 [leak_demo] 0x00000000004012bd main+0x18 [leak_demo] 0x00007fb870c29590 __libc_start_call_main+0x80 [libc.so.6] 21024768 bytes in 20 allocations from stack 0x00007fb870c980dd sysmalloc+0x7ed [libc.so.6] [10:43:38] Top 3 stacks with outstanding allocations: addr = 7fb86c2b7010 size = 15 addr = 7fb86ada2000 size = 1048576 addr = 7fb86b3a8000 size = 1048576 addr = 7fb86b7ac000 size = 1048576 .......................... addr = 7fb869186000 size = 1052672 addr = 7fb869a8f000 size = 1052672 addr = 7fb86a297000 size = 1052672 3153935 bytes in 4 allocations from stack 0x00000000004011ae allocate_memory+0x18 [leak_demo] 0x000000000040125f memory_leak_demo+0x23 [leak_demo] 0x00000000004012bd main+0x18 [leak_demo] 0x00007fb870c29590 __libc_start_call_main+0x80 [libc.so.6] 24182784 bytes in 23 allocations from stack 0x00007fb870c980dd sysmalloc+0x7ed [libc.so.6] ^C┌──[root@liruilongs.github.io]-[/usr/share/bcc/tools] └─$
持续增长的未释放内存块(如 1052672 字节 ≈1MB 的多次分配),通过 memleak 打印的 堆栈追踪指向 allocate_memory+0x18 和 memory_leak_demo+0x23 函数
1 2 3 4 5 3153935 bytes in 4 allocations from stack 0x00000000004011ae allocate_memory+0x18 [leak_demo] 0x000000000040125f memory_leak_demo+0x23 [leak_demo] 0x00000000004012bd main+0x18 [leak_demo] 0x00007fb870c29590 __libc_start_call_main+0x80 [libc.so.6]
正是上面 Demo 中的调用函数 memory_leak_demo()和分配函数 allocate_memory.
跟踪全系统的mmap系统调用 mmapsnoop mmapsnoop(8)跟踪全系统的mmap(2)系统调用并打印出映射请求的详细信息,这对内存映射调试来说是很有用的。
对应的代码地址:
https://github.com/brendangregg/bpf-perf-tools-book/blob/master/originals/Ch07_Memory/mmapsnoop.py
mmapsnoop 通过 eBPF 技术实现了对 Linux 系统内所有 mmap 系统调用的高效跟踪,揭示了:
进程如何通过内存映射访问文件或设备;
内存保护与共享机制的实时应用;
内核与用户态间的高效数据交互机制。
使用方式相对简单,直接通过命令行即可,我们看一个 Demo
下面的 Demo 创建一个匿名内存区域,一般这种场景,常用于分配大块的内存(如缓存、数据结构),进程间共享内存(需配合MAP_SHARED,但这里使用MAP_PRIVATE,内存不可共享),mmap仅分配虚拟地址空间,首次访问时才分配物理页(通过缺页中断)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 ┌──[root@liruilongs.github.io]-[~/bpfdemo] └─$cat anon2mmap.c #include <stdio.h> #include <stdlib.h> #include <sys/mman.h> #define GB ((long long) 1024 * 1024 * 1024) int main () long long size = 8 * GB; void *ptr = mmap(NULL , size, PROT_READ | PROT_WRITE, MAP_PRIVATE | MAP_ANONYMOUS, -1 , 0 ); if (ptr == MAP_FAILED) { perror("mmap failed" ); return 1 ; } for (long long i = 0 ; i < size; i += 4096 ) { ((char *)ptr)[i] = 'A' ; if (i % (GB) == 0 ) { printf ("Allocated %lld GB\n" , i / GB); } } printf ("Successfully mapped %lld GB\n" , size / GB); munmap(ptr, size); return 0 ; } ┌──[root@liruilongs.github.io]-[~/bpfdemo] └─$
如果 mmap 没有映射文件或者设备,不使用大页,那么默认使用标准内存页对齐的方式创建虚拟内存
这里通过循环向标准内存页(4KB)写入数据,选择 4KB(4096 字节)作为步长,是为了确保每个内存页只被访问一次。触发实际的物理内存分配(Linux 采用延迟分配策略,mmap仅分配虚拟地址,首次访问时触发缺页异常才分配物理页)
编译之后运行上面的程序,可以看到在物理内存在分配第 4 GB 内存时 触发了 OOM killer
1 2 3 4 5 6 7 8 ┌──[root@liruilongs.github.io]-[~/bpfdemo] └─$./anon2mmap Allocated 0 GB Allocated 1 GB Allocated 2 GB Allocated 3 GB Allocated 4 GB Killed
通过内核日志我们可以验证这一点, anon2mmap(PID=13365)尝试分配大量内存,导致系统内存耗尽。同时展示了,内存分配标志,OOM 评分等,以及触发 OOM killer 的函数调用栈
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 ┌──[root@liruilongs.github.io]-[~/bpfdemo] └─$dmesg --follow -T [Sat Jun 7 16:54:14 2025] anon2mmap invoked oom-killer: gfp_mask=0x140dca(GFP_HIGHUSER_MOVABLE|__GFP_COMP|__GFP_ZERO), order=0, oom_score_adj=0 [Sat Jun 7 16:54:14 2025] CPU: 1 PID: 13365 Comm: anon2mmap Kdump: loaded Tainted: G OE ------- --- 5.14.0-427.20.1.el9_4.x86_64 [Sat Jun 7 16:54:14 2025] Hardware name: VMware, Inc. VMware Virtual Platform/440BX Desktop Reference Platform, BIOS 6.00 11/12/2020 [Sat Jun 7 16:54:14 2025] Call Trace: [Sat Jun 7 16:54:14 2025] <TASK> [Sat Jun 7 16:54:14 2025] dump_stack_lvl+0x34/0x48 [Sat Jun 7 16:54:14 2025] dump_header+0x4a/0x201 [Sat Jun 7 16:54:14 2025] oom_kill_process.cold+0xb/0x10 [Sat Jun 7 16:54:14 2025] out_of_memory+0xed/0x2e0 [Sat Jun 7 16:54:14 2025] __alloc_pages_slowpath.constprop.0+0x6e8/0x960 [Sat Jun 7 16:54:14 2025] __alloc_pages+0x21d/0x250 [Sat Jun 7 16:54:14 2025] __folio_alloc+0x17/0x50 [Sat Jun 7 16:54:14 2025] ? policy_node+0x4f/0x70 [Sat Jun 7 16:54:14 2025] vma_alloc_folio+0xa3/0x390 [Sat Jun 7 16:54:14 2025] do_anonymous_page+0x63/0x520 [Sat Jun 7 16:54:14 2025] __handle_mm_fault+0x32b/0x670 [Sat Jun 7 16:54:14 2025] ? nohz_balancer_kick+0x31/0x250 [Sat Jun 7 16:54:14 2025] handle_mm_fault+0xcd/0x290 [Sat Jun 7 16:54:14 2025] do_user_addr_fault+0x1b4/0x6a0 [Sat Jun 7 16:54:14 2025] ? sched_clock_cpu+0x9/0xc0 [Sat Jun 7 16:54:14 2025] exc_page_fault+0x62/0x150 [Sat Jun 7 16:54:14 2025] asm_exc_page_fault+0x22/0x30 。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。 [Sat Jun 7 16:54:14 2025] Tasks state (memory values in pages): [Sat Jun 7 16:54:14 2025] [ pid ] uid tgid total_vm rss pgtables_bytes swapents oom_score_adj name [Sat Jun 7 16:54:14 2025] [ 701] 0 701 12852 192 114688 288 -250 systemd-journal [Sat Jun 7 16:54:14 2025] [ 715] 0 715 8274 32 98304 512 -1000 systemd-udevd [Sat Jun 7 16:54:14 2025] [ 887] 0 887 4539 80 57344 672 -1000 auditd 。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。 [Sat Jun 7 16:54:14 2025] [ 13058] 48 13058 374632 38 483328 16256 0 /usr/sbin/httpd [Sat Jun 7 16:54:14 2025] [ 13364] 0 13364 63300 2813 495616 12512 0 mmapsnoop [Sat Jun 7 16:54:14 2025] [ 13365] 0 13365 2097810 808956 9932800 424160 0 anon2mmap [Sat Jun 7 16:54:14 2025] oom-kill:constraint=CONSTRAINT_NONE,nodemask=(null),cpuset=/,mems_allowed=0,global_oom,task_memcg=/user.slice/user-0.slice/session-9.scope,task=anon2mmap,pid=13365,uid=0 [Sat Jun 7 16:54:14 2025] Out of memory: Killed process 13365 (anon2mmap) total-vm:8391240kB, anon-rss:3235696kB, file-rss:128kB, shmem-rss:0kB, UID:0 pgtables:9700kB oom_score_adj:0
虚拟内存总量 total-vm: 8391240kB(约 8GB),对应代码中的 8GB 内存申请
1 2 3 long long size = 8 * GB; void *ptr = mmap(NULL , size, PROT_READ | PROT_WRITE, MAP_PRIVATE | MAP_ANONYMOUS, -1 , 0 );
匿名物理内存 anon-rss: 3235696kB(约 3.2GB),对应触发OOM killer 的内存消耗
这里我们用 mmapsnoop 去跟踪 mmap 的匿名内存的分配
1 2 3 4 5 6 7 8 9 10 ┌──[root@liruilongs.github.io]-[/usr/share/bcc/tools] └─$./mmapsnoop -T TIME PID COMM PROT MAP OFFS(KB) SIZE(KB) FILE 00:42:09 13365 b'anon2mmap' R-- -P-- 0 28 b'ld.so.cache' 00:42:09 13365 b'anon2mmap' R-- -P-- 0 2083 b'libc.so.6' 00:42:09 13365 b'anon2mmap' R-E -PF- 160 1492 b'libc.so.6' 00:42:09 13365 b'anon2mmap' R-- -PF- 1652 352 b'libc.so.6' 00:42:09 13365 b'anon2mmap' RW- -PF- 2004 24 b'libc.so.6' ^C┌──[root@liruilongs.github.io]-[/usr/share/bcc/tools] └─$
这里脚本有一些问题,可以看到只能跟踪到一些共享库的分配,却看不到实际的匿名内存的分配,这是什么原因?
mmap 映射的匿名内存直接使用的虚拟内存,没有映射文件,所以之前的脚本没有记录这部分, 可以看到代码在 fd2file中没有关联的数据时,直接返回 0,即匿名映射的内存会直接忽略
1 2 3 4 5 6 7 8 9 TRACEPOINT_PROBE(syscalls, sys_enter_mmap) { ...................... fpp = fd2file.lookup(&key); if (fpp == 0 ) return 0 ; file = *fpp; ..................... return 0 ; }
这里我们需要修改一下原来的脚本,下面为修改之后的
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 TRACEPOINT_PROBE(syscalls, sys_enter_mmap) { u32 pid = bpf_get_current_pid_tgid() >> 32 ; struct fdkey_t key = const char *anon_name = "[anon]" ; bpf_trace_printk("DEBUG: mmap fd=%d, pid=%d ---" , args->fd, pid); long fd = (long )args->fd; if ( args->fd == 0xFFFFFFFF ) { struct mmap_data_t data = .len = args->len, .prot = args->prot, .flags = args->flags, .off = args->off, .pid = pid }; bpf_trace_printk("DEBUG: mmap len=%d, prot=%d ---" , args->len, args->prot); bpf_get_current_comm(&data.comm, sizeof (data.comm)); bpf_probe_read(&data.path, sizeof (data.path), (void *)anon_name); mmap_events.perf_submit(args, &data, sizeof (data)); return 0 ; } struct file **fpp = if (fpp == 0 ) return 0 ; struct file *file = struct mmap_data_t data = .len = args->len, .prot = args->prot, .flags = args->flags, .off = args->off, .pid = pid }; bpf_get_current_comm(&data.comm, sizeof (data.comm)); struct dentry *de = struct qstr d_name = bpf_probe_read(&d_name, sizeof (d_name), (void *)&de->d_name); bpf_probe_read(&data.path, sizeof (data.path), d_name.name); mmap_events.perf_submit(args, &data, sizeof (data)); return 0 ; }
分配匿名内存的时候 args->fd 的值为 -1, 需要注意 这里的 if ( args->fd == 0xFFFFFFFF ) ,需要用 32 位的 -1 表示
bpf_trace_printk 用于调试,输出会写入 /sys/kernel/debug/tracing/trace_pipe
下面是修改之后的输出
1 2 3 4 5 6 7 8 9 10 11 12 13 ┌──[root@liruilongs.github.io]-[/usr/share/bcc/tools] └─$./ano_mmapsoonp PID COMM PROT MAP OFFS(KB) SIZE(KB) FILE 49103 ano_mmapsoonp RW- S--- 0 260 [perf_event] 49104 anon2mmap RW- -P-A 0 8 49104 anon2mmap R-- -P-- 0 28 ld.so.cache 49104 anon2mmap R-- -P-- 0 2083 libc.so.6 49104 anon2mmap R-E -PF- 160 1492 libc.so.6 49104 anon2mmap R-- -PF- 1652 352 libc.so.6 49104 anon2mmap RW- -PF- 2004 24 libc.so.6 49104 anon2mmap RW- -PFA 0 51 49104 anon2mmap RW- -P-A 0 12 49104 anon2mmap RW- -P-A 0 8388608
可以看到最后一条日志,对应分配虚拟内存 8388608KB/1024/1024 = 8G
1 `49104 anon2mmap RW- -P-A 0 8388608`
下面为调试日志的输出
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 ^C┌──[root@liruilongs.github.io]-[/usr/share/bcc/tools] └─$ cat /sys/kernel/debug/tracing/trace_pipe ano_mmapsoonp-49103 [000] ....2.1 591493.415773: bpf_trace_printk: DEBUG: mmap fd=-1, pid=49103 --- ano_mmapsoonp-49103 [000] ....2.1 591493.415802: bpf_trace_printk: DEBUG: mmap len=4096, prot=7 --- ano_mmapsoonp-49103 [000] ....2.1 591493.415963: bpf_trace_printk: DEBUG: mmap fd=12, pid=49103 --- ano_mmapsoonp-49103 [000] ....2.1 591493.416216: bpf_trace_printk: DEBUG: mmap fd=13, pid=49103 --- anon2mmap-49104 [001] ....2.1 591496.676898: bpf_trace_printk: DEBUG: mmap fd=-1, pid=49104 --- anon2mmap-49104 [001] ....2.1 591496.676906: bpf_trace_printk: DEBUG: mmap len=8192, prot=3 --- ....................................... anon2mmap-49104 [001] ....2.1 591496.680823: bpf_trace_printk: DEBUG: mmap fd=-1, pid=49104 --- anon2mmap-49104 [001] ....2.1 591496.680849: bpf_trace_printk: DEBUG: mmap len=0, prot=3 --- systemd-journal-701 [000] ....2.1 591502.486094: bpf_trace_printk: DEBUG: mmap fd=22, pid=701 --- in :imjournal-1173 [001] ....2.1 591502.744724: bpf_trace_printk: DEBUG: mmap fd=8, pid=1144 --- ^C ┌──[root@liruilongs.github.io]-[/usr/share/bcc/tools] └─$
mmapfiles(8) mmapfles(8) 是一个 bpftrace 工具,同样用于跟踪 mmap(2) 调用,主要统计映射入内存地址范围的文件频率信息, 可以通过这个命令直观的看到频繁分配的进程数据
对应的代码地址:
https://github.com/brendangregg/bpf-perf-tools-book/blob/master/originals/Ch08_FileSystems/mmapfiles.bt
这里我们执行一些前面写的 Demo,看下输出
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 ┌──[root@liruilongs.github.io]-[/usr/share/bpftrace/tools] └─$./mmapfiles.bt Attaching 1 probe... ^C @[locale, C.utf8, LC_PAPER]: 1 @[/, /, my_shared_memory]: 1 。。。。。。。。。。。 @[root, bpfdemo, testfile.txt]: 1 。。。。。。。。。。。。。。。。。。。。 @[locale, C.utf8, LC_ADDRESS]: 1 @[anon_hugepage, anon_hugepage, anon_hugepage]: 2 @[root, bpfdemo, file2mmap]: 4 @[root, bpfdemo, anonhag2mmap]: 4 @[usr, lib64, libpcre2-8.so.0.11.0]: 4 @[root, bpfdemo, shar2mmap]: 4 @[usr, lib64, libselinux.so.1]: 4 @[usr, lib64, libcap.so.2.48]: 4 @[usr, bin, ls]: 4 @[root, bpfdemo, hug2mmap]: 4 ┌──[root@liruilongs.github.io]-[/usr/share/bpftrace/tools] └─$
前两个列为 当前程序的两个父目录信息,root, bpfdemo,我们的实验在 root 目录的 bpfdemo 目录下完成,第三列为映射的进程名字,最后一列为映射次数
fmapfaults(8) fmapfault(8) 跟踪内存映射文件的缺页错误,按进程名和文件名来统计,内存映射了之后只有写入数据才会发生缺页错误,所以如果我们想知道那些进程在分配虚拟内存之后进行了读写操作,那么可以通过 fmapfaults 跟踪。
对应的代码地址:
https://github.com/brendangregg/bpf-perf-tools-book/blob/master/originals/Ch08_FileSystems/fmapfault.bt
这里任然使用之前的 Demo 进行测试
1 2 3 4 5 6 7 8 9 10 11 12 ┌──[root@liruilongs.github.io]-[~/bpfdemo] └─$./shar2mmap Parent read : Hello from child process! PID=15816 ┌──[root@liruilongs.github.io]-[~/bpfdemo] └─$./hug2mmap ┌──[root@liruilongs.github.io]-[~/bpfdemo] └─$./file2mmap 当前进程PID: 15818 Original file content: ABCD.............................IJ ┌──[root@liruilongs.github.io]-[~/bpfdemo] └─$
需要注意,文件实际的读写操作频率可能高于缺页错误发生的频率。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 ┌──[root@liruilongs.github.io]-[/usr/share/bpftrace/tools] └─$./fmapfault.bt Attaching 1 probe... ^C @[file2mmap, libc.so.6]: 1 @[shar2mmap, shar2mmap]: 1 @[file2mmap, file2mmap]: 1 @[shar2mmap, libc.so.6]: 1 @[file2mmap, testfile.txt]: 1 @[hug2mmap, hug2mmap]: 1 @[hug2mmap, libc.so.6]: 1 @[hug2mmap, ld-linux-x86-64.so.2]: 4 @[file2mmap, ld-linux-x86-64.so.2]: 4 @[shar2mmap, ld-linux-x86-64.so.2]: 4 ┌──[root@liruilongs.github.io]-[/usr/share/bpftrace/tools] └─$
跟踪用户态小内存 brk 分配调用栈 一般来说,应用程序的数据存放于堆内存中,堆内存通过brk(2)系统调用进行扩展,对于比较常见的 libc 分配器的 malloc 等函数,在内存分配,小内存块使用 brk 分配,一般在空闲列表耗尽时,会上移堆顶指针,扩展虚拟地址空间,对于大块内存,直接调用我们上篇博文讲的 mmap 方式,创建独立的内存段,一般按页对齐,直接映射进程虚拟地址空间。
通过跟踪 brk(2)调用,可以展示对应的用户态调用栈信息,已经调用次数统计。同时还有一个sbrk(2)变体调用。在Linux中,sbrk(2)是以库函数形式实现的,内部仍然使用 brk(2)系统调用。
跟踪 brk(2) 调用的方式有很多,可以通过静态跟踪 tracepoint 对 syscall:syscall_enter_brk 内核跟踪点来跟踪,用 BCC版本的trace(8)来获取每个事件的信息,也可以用stackcount(8)来获取频率统计信息,还可以用bpfrace 版本的单行程序来获取,甚至可以用perf(1)命令获取。
这里先准备一个测试脚本,调用 malloc 函数多次分配内存,观察 sbrk(0) 的变化
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 ┌──[root@liruilongs.github.io]-[~/bpfdemo] └─$cat ./malloc_free.c // demo3_malloc_free.c int main printf ("PID = %d\n" , getpid()); printf ("Before malloc: brk = %p\n" , sbrk(0)); // 分配大块内存(可能触发 brk 增长) void *ptr1 = malloc (12 * 1024); // 12KB printf ("After malloc 12KB: brk = %p\n" , sbrk(0)); // 再分配小块内存 void *ptr2 = malloc(120* 1024); // 120KB printf ("After malloc 120KB: brk = %p\n" , sbrk(0)); // 再分配小块内存 void *ptr3 = malloc(4 * 1024); // 4KB printf ("After malloc 4KB: brk = %p\n" , sbrk(0)); sleep(30); return 0; }
sbrk(0) 为当前堆顶指针,每次分配内存,堆顶指针都会增加,这里分配了 12KB,120KB,4KB,观察堆顶指针的变化。
1 2 3 4 5 6 7 8 9 10 11 12 ┌──[root@liruilongs.github.io]-[~/bpfdemo] └─$vim malloc_free.c ┌──[root@liruilongs.github.io]-[~/bpfdemo] └─$gcc -g malloc_free.c -o malloc_free ┌──[root@liruilongs.github.io]-[~/bpfdemo] └─$./malloc_free PID = 2916 Before malloc: brk = 0x1ae2000 After malloc 12KB: brk = 0x1ae2000 After malloc 120KB: brk = 0x1b03000 After malloc 4KB: brk = 0x1b03000 ^C
可以看到上面的输出,只有在分配120KB的时候,堆顶指针发生了变化(0x1ae2000 -> 0x1b03000),说明进行了堆内存的扩展,brk(2)系统调用被调用了。其他位置虽然也有调用,但是并不是进行了堆扩展。
trace trace 命令是一个 BCC 工具,可以对多个数据源进行跟踪。这里我们使用它来跟踪 内核态跟踪点 sys_enter_brk
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 ┌──[root@liruilongs.github.io]-[~/bpfdemo] └─$./malloc_free PID = 3098 Before malloc: brk = 0x15cf000 After malloc 12KB: brk = 0x15cf000 After malloc 120KB: brk = 0x15f0000 After malloc 4KB: brk = 0x15f0000 ^C ┌──[root@liruilongs.github.io]-[/usr/share/bpftrace/tools] └─$/usr/share/bcc/tools/trace -U 't:syscalls:sys_enter_brk "brk(0x%lx)", args->brk' PID TID COMM FUNC - 3098 3098 malloc_free sys_enter_brk brk(0x0) brk+0xb [ld-linux-x86-64.so.2] [unknown] [ld-linux-x86-64.so.2] 3098 3098 malloc_free sys_enter_brk brk(0x0) brk+0xb [libc.so.6] 3098 3098 malloc_free sys_enter_brk brk(0x15cf000) brk+0xb [libc.so.6] 3098 3098 malloc_free sys_enter_brk brk(0x15f0000) brk+0xb [libc.so.6] ^C
我们来分析一下上面的输出
brk (0x15f0000) 调用:对应于程序中第二次 120KB 的内存分配,移动了 brk 指针来扩大堆空间。
剩下的 brk 调用,前面两次调用,可能是程序启动时的初始化调用。第三次调用可能是 libc 的内部管理
stackcount 我们通过 stackcount 来统计 brk 调用的次数,确认上面的输出
stackcount(8)也是一个综合工具,可以对导致某事件发生的函数调用栈进行计数。和trace(8)一样,事件源可以是内核态或用户态函数、内核跟踪点或者USDT探针。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 ┌──[root@liruilongs.github.io]-[~/bpfdemo] └─$./malloc_free PID = 2918 Before malloc: brk = 0x1ca4000 After malloc 12KB: brk = 0x1ca4000 After malloc 120KB: brk = 0x1cc5000 After malloc 4KB: brk = 0x1cc5000 ^C ┌──[root@liruilongs.github.io]-[/usr/share/bcc/tools] └─$/usr/share/bcc/tools/stackcount -TPU t:syscalls:sys_enter_brk Tracing 1 functions for "t:syscalls:sys_enter_brk" ... Hit Ctrl-C to end. ^C 15:15:12 brk [unknown] b'malloc_free' [2918] 1 brk b'malloc_free' [2918] 3 Detaching...
可以看到调用栈,总共有 4 次 brk 调用,其中 3 次直接来自应用程序,1 次通过未知库路径(可能是动态链接器)
brkstack brkstack 是一个 bpftrace 工具,可以跟踪堆内存分配,包括堆内存的分配和释放。它使用 bpftrace 的 tracepoint 机制,跟踪内核中的 sys_enter_brk事件。
代码地址
https://github.com/brendangregg/bpf-perf-tools-book/blob/master/originals/Ch07_Memory/brkstack.bt
1 2 3 4 5 6 7 8 9 10 11 12 13 #!/usr/local/bin/bpftrace /* * brkstack - Count brk(2) syscalls with user stacks. * * See BPF Performance Tools, Chapter 7, for an explanation of this tool. ...... * 26-Jan-2019 Brendan Gregg Created this. */ tracepoint:syscalls:sys_enter_brk { @[ustack, comm] = count(); }
代码比较简单,实际上和上面的工具类似,可以看作是上面两个工具的结合
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 ┌──[root@liruilongs.github.io]-[~/bpfdemo] └─$./malloc_free PID = 2978 Before malloc: brk = 0x14d7000 After malloc 12KB: brk = 0x14d7000 After malloc 120KB: brk = 0x14f8000 After malloc 4KB: brk = 0x14f8000 ^C ┌──[root@liruilongs.github.io]-[/usr/share/bpftrace/tools] └─$./brkstack.bt Attaching 1 probe... ^C @[2978, __brk+11 0x7f7fc5a42b68 , malloc_free]: 1 @[2978, brk+11 , malloc_free]: 3 ┌──[root@liruilongs.github.io]-[/usr/share/bpftrace/tools] └─$
进行了一次堆扩展,所以调用了一次,但是包含着最后三次的中,这里的 Demo 是分配的三次内存,会不会对应 三次 brk 调用? 可以修改上面的脚本验证这一点
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 ┌──[root@liruilongs.github.io]-[~/bpfdemo] └─$cat malloc_free.c // demo3_malloc_free.c int main printf ("PID = %d\n" , getpid()); printf ("Before malloc: brk = %p\n" , sbrk(0)); // 分配大块内存(可能触发 brk 增长) void *ptr1 = malloc (12 * 1024); // 12KB printf ("After malloc 12KB: brk = %p\n" , sbrk(0)); // 再分配小块内存 void *ptr2 = malloc(120* 1024); // 120KB printf ("After malloc 120KB: brk = %p\n" , sbrk(0)); // 再分配小块内存 void *ptr3 = malloc(4 * 1024); // 4KB printf ("After malloc 4KB: brk = %p\n" , sbrk(0)); void *ptr4 = malloc(4 * 1024); // 4KB printf ("After malloc 4KB: brk = %p\n" , sbrk(0)); void *ptr5 = malloc(120 * 1024); // 4KB printf ("After malloc 120KB: brk = %p\n" , sbrk(0)); sleep(30); return 0; } ┌──[root@liruilongs.github.io]-[~/bpfdemo] └─$
运行之后发现,多次内存分配,但是堆还是只扩展了一次,而且 brk 的调用次数也没有发生改变,还是3 次,所以可以验证我们上面的猜测
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 ┌──[root@liruilongs.github.io]-[~/bpfdemo] └─$./malloc_free PID = 2335 Before malloc: brk = 0x1a46000 After malloc 12KB: brk = 0x1a46000 After malloc 120KB: brk = 0x1a67000 After malloc 4KB: brk = 0x1a67000 After malloc 4KB: brk = 0x1a67000 After malloc 120KB: brk = 0x1a67000 ^C ┌──[root@liruilongs.github.io]-[/usr/share/bpftrace/tools] └─$./brkstack.bt Attaching 1 probe... ^C @[2335, __brk+11 0x7f1a6dc89b68 , malloc_free]: 1 @[2335, brk+11 , malloc_free]: 3
这里我们可以看到对于小内存的分配,如果发生的堆扩展,那么我们可以 brk 相关的工具来进行跟踪,如果是通过空闲列表直接获取,那么没有办法跟踪。
SystemV的共享内存的调用跟踪 SystemV 共享内存是 Linux 系统中一种高效的进程间通信(IPC)机制,允许多个进程直接访问同一块物理内存区域, 对共享内存的跟踪 主要使用 shmsnoop BCC 工具,可以跟踪 SystemV的共享内存系统调用:shmget(2)、shmat(2)、shmdt(2)以及 shmctl(2)。这个工具可以用来调试共享内存的用量信息。下面为在一台云主机上执行后的输出
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 [root@liruilongs.github.io tools] PID COMM SYS RET ARGs 1710 xfwm4 SHMDT 0 shmaddr: 0xffffb1467000 1710 xfwm4 SHMGET 27 key: 0x0, size: 524288, shmflg: 0x380 (IPC_CREAT|0600) 1710 xfwm4 SHMAT ffffb1467000 shmid: 0x27, shmaddr: 0x0, shmflg: 0x0 1710 xfwm4 SHMCTL 0 shmid: 0x27, cmd: 0, buf: 0x0 1304 Xvnc SHMDT 0 shmaddr: 0xffffaeb64000 1304 Xvnc SHMAT ffffaeb64000 shmid: 0x27, shmaddr: 0x0, shmflg: 0x0 1304 Xvnc SHMCTL 0 shmid: 0x27, cmd: 2, buf: 0xffffc64e9348 1710 xfwm4 SHMDT 0 shmaddr: 0xffffb1467000 1710 xfwm4 SHMGET 28 key: 0x0, size: 524288, shmflg: 0x380 (IPC_CREAT|0600) 1710 xfwm4 SHMAT ffffb1467000 shmid: 0x28, shmaddr: 0x0, shmflg: 0x0 1710 xfwm4 SHMCTL 0 shmid: 0x28, cmd: 0, buf: 0x0 1304 Xvnc SHMDT 0 shmaddr: 0xffffaeb64000 1304 Xvnc SHMAT ffffaeb64000 shmid: 0x28, shmaddr: 0x0, shmflg: 0x0 1304 Xvnc SHMCTL 0 shmid: 0x28, cmd: 2, buf: 0xffffc64e9348
这里我们看一个 Demo,创建共享内存,附加到进程虚拟地址空间
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 ┌──[root@liruilongs.github.io]-[~/bpfdemo] └─$cat shm.c #include <stdio.h> #include <stdlib.h> #include <string.h> #include <sys/ipc.h> #include <sys/shm.h> #define SHM_SIZE 1024 #define SHM_KEY 0x1234 int main () int shmid; char *shmaddr; shmid = shmget(SHM_KEY, SHM_SIZE, 0666 | IPC_CREAT); if (shmid == -1 ) { perror("shmget failed" ); exit (EXIT_FAILURE); } printf ("Shared memory created with ID: %d\n" , shmid); shmaddr = shmat(shmid, NULL , 0 ); if (shmaddr == (char *)-1 ) { perror("shmat failed" ); exit (EXIT_FAILURE); } printf ("Shared memory attached at address: %p\n" , shmaddr); strcpy (shmaddr, "Hello from shared memory!" ); printf ("Data written: %s\n" , shmaddr); if (shmdt(shmaddr) == -1 ) { perror("shmdt failed" ); exit (EXIT_FAILURE); } printf ("Shared memory detached\n" ); if (shmctl(shmid, IPC_RMID, NULL ) == -1 ) { perror("shmctl(IPC_RMID) failed" ); exit (EXIT_FAILURE); } printf ("Shared memory deleted\n" ); return 0 ; } ┌──[root@liruilongs.github.io]-[~/bpfdemo] └─$
下面为运行程序的输出
1 2 3 4 5 6 7 ┌──[root@liruilongs.github.io]-[~/bpfdemo] └─$./shm Shared memory created with ID: 2 Shared memory attached at address: 0x7fc2a1a6d000 Data written: Hello from shared memory! Shared memory detached Shared memory deleted
shmsnoop 输出部分参数说明
key: 0x1234 共享内存的键值(用于进程间识别)7f4477be4000(共享内存在进程中的虚拟地址)
SystemV 共享内存操作流程:
创建 / 获取共享内存(SHMGET):通过唯一键值创建或获取共享内存段,返回 ID附加到进程地址空间(SHMAT):将共享内存映射到进程虚拟地址,返回映射地址数据交互:进程通过映射地址读写共享内存(输出中未显示具体数据操作)分离共享内存(SHMDT):进程不再使用时断开映射控制操作(SHMCTL):管理共享内存属性(如删除、修改权限等)
1 2 3 4 5 6 7 8 9 ┌──[root@liruilongs.github.io]-[/usr/share/bcc/tools] └─$./shmsnoop PID COMM SYS RET ARGs 3413 shm SHMGET 3 key: 0x1234, size: 1024, shmflg: 0x3b6 (IPC_CREAT|0666) 3413 shm SHMAT 7f4477be4000 shmid: 0x3, shmaddr: 0x0, shmflg: 0x0 3413 shm SHMDT 0 shmaddr: 0x7f4477be4000 3413 shm SHMCTL 0 shmid: 0x3, cmd: 0, buf: 0x0 ^C┌──[root@liruilongs.github.io]-[/usr/share/bcc/tools] └─$
当Linux 启动一个程序时,会先给程序分配合适的虚拟地址空间,也就是我们申请的内存大小,不会把所有虚拟地址空间都映射到物理内存,而是把程序在运行中需要的数据,映射到物理内存,需要时可以再动态映射分配物理内存
因为每个进程都维护着自己的虚拟地址空间,每个进程都有一个页表来定位虚拟内存到物理内存的映射,每个虚拟内存也在表中都有一个对应的条目
当进程访问虚拟地址,但是在映射的页面中查不到对应的物理地址时,内核就会产生一个缺页异常(Page Fault),此时会重新分配物理内存,更新映射页表。
在内存访问中,在验证页表项通过之后,查询页表数据标记为不存在,会促发缺页中断,会重新分配物理页帧(从空闲内存或通过页面置换算法如 LRU 淘汰旧页),或者磁盘(如交换分区或文件)加载数据到物理页帧,更新页表项,标记为有效,重新执行触发缺页的指令。
通过页表项获得物理页帧基地址,加上虚拟地址中的页内偏移,可以得到最终物理地址。MMU 将物理地址发送到内存总线,CPU 读取或写入物理内存,同时会更新 TLB,下次使用直接读取 TLB的数据。
内核产生一个 page fault 异常事件分为两种:
minor fualt
当进程缺页事件发生在第一次访问虚拟内存时,虚拟内存已分配但未映射(如首次访问、写时复制、共享内存同步)物理地址,内核会产生一个 minor page fualt,并分配新的物理内存页。minor page fault 产生的开销比较小,minor page fualt 典型场景:
首次访问:进程申请内存后,内核延迟分配物理页(Demand Paging),首次访问时触发。写时复制(COW):fork()创建子进程时共享父进程内存,子进程写操作前触发共享库加载:动态链接库被多个进程共享,首次加载到物理内存时触发,即会共享页表
major fault
当物理页未分配且需从磁盘(Swap分区或文件)加载数据,内核就会产生一个 majorpage fault,比如内核通过Swap分区,将内存中的数据交换出去放到了硬盘,需要时从硬盘中重新加载程序或库文件的代码到内存。涉及到磁盘I/O,因此一个major fault对性能影响比较大,典型场景有
Swap In:物理内存不足时,内核将内存页换出到 Swap 分区,再次访问需换回。文件映射(mmap):通过 mmap 映射文件到内存,首次访问文件内容需从磁盘读取。
Minor Fault 是内存层面的轻量级操作,涉及到实际的物理内存分配,也是今天我们要跟踪的,Major Fault 是涉及磁盘I/O的重型操作。频繁的 Major Fault 就需要考虑性能问题, 对于缺页异常,我们可以通过传统工具比如 ps、vmstat、perf等工具来定位性能瓶颈
下面是我们实验用到的一个 Demo ,通过 perf 跟踪缺页异常
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 ┌──[root@liruilongs.github.io]-[~/bpfdemo] └─$perf stat -e minor-faults,major-faults ./anon2mmap PID = 13619 Allocated 0 GB Allocated 1 GB Allocated 2 GB Allocated 3 GB Allocated 4 GB Allocated 5 GB Allocated 6 GB Allocated 7 GB Total iterations: 2097152 Successfully mapped 8 GB ^C./anon2mmap: Interrupt Performance counter stats for './anon2mmap' : 4152 minor-faults 0 major-faults 22.012862749 seconds time elapsed 0.034524000 seconds user 3.493099000 seconds sys ┌──[root@liruilongs.github.io]-[~/bpfdemo] └─$
anon2mmap 通过 mmap 分配了8GB匿名内存,可以看到用户态CPU耗时 0.03,内核态 CPU 时间 3.49,缺页异常主要发生在 minor,实际中当前的生产环境中,考虑 交换分区的性能问题,一般在会准备机器的时候关闭交换分区。在内存使用中通过 Cgroup 对资源进行限制。通过 Qos 合理控制内存的超售问题
下面是我们测试用的 Demo,通过 mmap 分配一大块匿名内存,然后填充数据触发缺页异常,下面所有的Demo 都基于这个程序
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 ┌──[root@liruilongs.github.io]-[~/bpfdemo] └─$cat anon2mmap.c int main printf ("PID = %d\n" , getpid()); //sleep(30); long long size = 8 * GB; // 映射64MB内存 void *ptr = mmap(NULL, size, PROT_READ | PROT_WRITE, MAP_PRIVATE | MAP_ANONYMOUS, -1, 0); if (ptr == MAP_FAILED) { perror("mmap failed" ); return 1; } // 填充数据以触发实际内存分配 for (long long i = 0; i < size; i += 4096) { ((char *)ptr)[i] = 'A' ; if (i % (GB) == 0) { // printf ("Allocated %lld GB\n" , i / GB); } } printf ("Successfully mapped %lld GB\n" , size / GB); munmap(ptr, size); return 0; } ┌──[root@liruilongs.github.io]-[~/bpfdemo] └─$
跟踪缺页错误和对应的调用栈信息,可以为内存用量分析提供一个新的视角,不同于我们之前讲的 brk 和 mmap 是虚拟内存分配的角度去分析内存用量,缺页异常会直接影响系统常驻内存的的增长,也就是物理内存的增长。
跟踪方式主要利用内核静态跟踪点以及软件跟踪点
1 2 3 4 5 ┌──[root@liruilongs.github.io]-[~/bpfdemo] └─$sudo perf list | grep page_fault exceptions:page_fault_kernel [Tracepoint event] exceptions:page_fault_user [Tracepoint event] iommu:io_page_fault [Tracepoint event]
软件跟踪点,实际上也是基于内核静态跟踪点,对多种缺页异常进行统计
1 2 3 4 5 ┌──[root@liruilongs.github.io]-[~/bpfdemo] └─$ ┌──[root@liruilongs.github.io]-[~/bpfdemo] └─$perf list | grep page-faults page-faults OR faults [Software event]
stackcount stackcount 可能是我们用的最多的一个 BPF 工具,用于对特定函数进行跟踪,可以是静态跟踪点,也可以是动态跟踪点,下面的命令, -p 指定进程ID,后面为内核静态跟踪点的表达式,这里跟踪用户态的缺页异常 page_fault_user
1 2 3 4 5 6 7 8 9 10 11 12 ┌──[root@liruilongs.github.io]-[~/bpfdemo] └─$/usr/share/bcc/tools/stackcount -p 9147 t:exceptions:page_fault_user Tracing 1 functions for "t:exceptions:page_fault_user" ... Hit Ctrl-C to end. ^C exc_page_fault exc_page_fault asm_exc_page_fault [unknown] [unknown] 4096 Detaching...
默认情况下会同时输出 用户态和内核态的调用栈,内核态调用栈显示缺页异常由 asm_exc_page_fault(汇编层入口)触发,最终调用exc_page_fault(缺页处理函数)。[unknown] 表示用户态调用栈未捕获或符号解析失败,4096 表示该调用路径发生了 4096 次缺页事件。
添加 -U 选项,只输出用户态的调用栈数据,但是这里的用户态调用栈没有解析出函数名
1 2 3 4 5 6 7 8 9 10 11 ┌──[root@liruilongs.github.io]-[~/bpfdemo] └─$/usr/share/bcc/tools/stackcount -p 9190 -U t:exceptions:page_fault_user Tracing 1 functions for "t:exceptions:page_fault_user" ... Hit Ctrl-C to end. ^C [unknown] [unknown] 4096 Detaching... ┌──[root@liruilongs.github.io]-[~/bpfdemo] └─$
trace trace 也是一个比较常用的 BPF 工具,用于跟踪函数调用时函数签名相关信息,通过 trace 我们可以获取用户态的调用栈,解决上面的问题,运行程序 Demo
1 2 3 4 5 6 7 8 9 10 11 12 13 ┌──[root@liruilongs.github.io]-[~/bpfdemo] └─$./anon2mmap PID = 9261 Allocated 0 GB Allocated 1 GB Allocated 2 GB Allocated 3 GB Allocated 4 GB Allocated 5 GB Allocated 6 GB Allocated 7 GB Total iterations: 2097152 Successfully mapped 8 GB
通过 trace 来跟踪缺页函数调用,通上面的 stackcount 工具我们可以知道调用了 4096 次缺页分配函数,所以通过 teace 跟踪可以看到很多数据,这里我们只展示部分
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 ┌──[root@liruilongs.github.io]-[~/bpfdemo] └─$/usr/share/bcc/tools/trace -p 9261 -U t:exceptions:page_fault_user PID TID COMM FUNC .................... 9261 9261 anon2mmap page_fault_user main+0x99 [anon2mmap] __libc_start_call_main+0x80 [libc.so.6] 9261 9261 anon2mmap page_fault_user main+0x99 [anon2mmap] __libc_start_call_main+0x80 [libc.so.6] 9261 9261 anon2mmap page_fault_user main+0x99 [anon2mmap] __libc_start_call_main+0x80 [libc.so.6] 9261 9261 anon2mmap page_fault_user main+0x99 [anon2mmap] __libc_start_call_main+0x80 [libc.so.6] 9261 9261 anon2mmap page_fault_user main+0x99 [anon2mmap] __libc_start_call_main+0x80 [libc.so.6] 9261 9261 anon2mmap page_fault_user main+0x99 [anon2mmap] __libc_start_call_main+0x80 [libc.so.6] 9261 9261 anon2mmap page_fault_user main+0x99 [anon2mmap] __libc_start_call_main+0x80 [libc.so.6] 9261 9261 anon2mmap page_fault_user main+0x99 [anon2mmap] __libc_start_call_main+0x80 [libc.so.6] 9261 9261 anon2mmap page_fault_user main+0x99 [anon2mmap] __libc_start_call_main+0x80 [libc.so.6] ............................................ 9261 9261 anon2mmap page_fault_user main+0x99 [anon2mmap] __libc_start_call_main+0x80 [libc.so.6] 9261 9261 anon2mmap page_fault_user main+0x99 [anon2mmap] __libc_start_call_main+0x80 [libc.so.6] 9261 9261 anon2mmap page_fault_user main+0x99 [anon2mmap] __libc_start_call_main+0x80 [libc.so.6]
PID 9261(进程名 anon2mmap)频繁触发用户态缺页异常(page_fault_user),每次缺页异常的调用栈完全相同,表明所有缺页均源于 main 函数的同一代码位置(偏移 0x99),可能是循环或重复操作中访问未映射的内存区域,
通过 free 命令可以实时的观察 物理内存得变化
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 ┌──[root@liruilongs.github.io]-[~] └─$free -h -s 0.1 -c 1000 total used free shared buff/cache available Mem: 15Gi 856Mi 14Gi 11Mi 649Mi 14Gi Swap: 2.0Gi 0B 2.0Gi total used free shared buff/cache available Mem: 15Gi 2.0Gi 12Gi 11Mi 649Mi 13Gi Swap: 2.0Gi 0B 2.0Gi total used free shared buff/cache available Mem: 15Gi 3.3Gi 11Gi 11Mi 649Mi 12Gi Swap: 2.0Gi 0B 2.0Gi total used free shared buff/cache available Mem: 15Gi 4.4Gi 10Gi 11Mi 649Mi 10Gi Swap: 2.0Gi 0B 2.0Gi total used free shared buff/cache available Mem: 15Gi 5.6Gi 9.3Gi 11Mi 649Mi 9.7Gi Swap: 2.0Gi 0B 2.0Gi total used free shared buff/cache available Mem: 15Gi 6.6Gi 8.3Gi 11Mi 649Mi 8.7Gi Swap: 2.0Gi 0B 2.0Gi total used free shared buff/cache available Mem: 15Gi 7.7Gi 7.2Gi 11Mi 649Mi 7.6Gi Swap: 2.0Gi 0B 2.0Gi total used free shared buff/cache available Mem: 15Gi 8.5Gi 6.4Gi 11Mi 649Mi 6.8Gi Swap: 2.0Gi 0B 2.0Gi total used free shared buff/cache available Mem: 15Gi 852Mi 14Gi 11Mi 649Mi 14Gi Swap: 2.0Gi 0B 2.0Gi
faults faults 是一个 bpftrace 工具,通过统计软件跟踪点,对缺页异常进行统计,同时会输出缺页异常的调用栈,可以看作是上面两个工具的结合
下面的代码地址
https://github.com/brendangregg/bpf-perf-tools-book/blob/master/originals/Ch07_Memory/faults.bt
使用了 Linux 的 perf stat命令来收集关于 sleep 2 命令执行期间的性能计数器统计信息
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 ┌──[root@liruilongs.github.io]-[~] └─$perf stat sleep 2 Performance counter stats for 'sleep 2' : 12.04 msec task-clock 1 context-switches 1 cpu-migrations 74 page-faults 3,328,860 cycles 0 instructions 289,196 branches 12,686 branch-misses 2.034208658 seconds time elapsed 0.000000000 seconds user 0.032226000 seconds sys ┌──[root@liruilongs.github.io]-[~] └─$
统计信息的解释:
task-clock:任务时钟,表示命令执行的总时间(以毫秒为单位)。context-switches:上下文切换次数,表示在命令执行期间发生的进程上下文切换次数。cpu-migrations:CPU 迁移次数,表示在命令执行期间发生的进程在不同 CPU 之间的迁移次数。page-faults:缺页错误次数,表示在命令执行期间发生的内存页面错误次数(可以简单理解为类似缓存穿透)
缺页错误来自哪些文件? faults(8) 也是一个 bpftrace 工具,根据文件名来跟踪缺页错误,这里的文件名,是一些文件映射内存的场景,如果使用匿名内存是无法跟踪的。
代码地址:
https://github.com/brendangregg/bpf-perf-tools-book/blob/master/originals/Ch07_Memory/ffaults.bt
这个工具使用 kprobes 来跟踪 handle_mm_fault() 内核函数,并且从该函数的调用参数中提取文件名信息。文件相关的缺页错误的出现频率和系统上运行的程序有关;
我们使用之前的程序测试,跟踪发现无法获取文件名,应该是匿名内存的原因,但是可以统计缺页函数调用次数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 ┌──[root@liruilongs.github.io]-[~/bpfdemo] └─$./anon2mmap PID = 14284 Allocated 0 GB .............. Total iterations: 2097152 Successfully mapped 8 GB ┌──[root@liruilongs.github.io]-[~/bpfdemo] └─$ ┌──[root@liruilongs.github.io]-[/usr/share/bpftrace/tools] └─$./ffaults.bt Attaching 1 probe... ^C @[]: 4096
对上面的 bpftrace 脚本做简单的修改
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 ┌──[root@liruilongs.github.io]-[/usr/share/bpftrace/tools] └─$cat ffaults1.bt kprobe:handle_mm_fault { $vma = (struct vm_area_struct *)arg0; // 关键修复:检查指针有效性需用 != 0 而非隐式判断 [1,3](@ref) if ($vma ->vm_file != 0) { $file = str($vma ->vm_file->f_path.dentry->d_name.name); } else { $file = "anonymous" ; // 标记匿名内存(堆/栈) } @[comm, pid, $file ] = count(); } END { printf ("%-16s %-8s %-40s %s\n" , "COMM" , "PID" , "FILE" , "FAULTS" ); //print (@); } ┌──[root@liruilongs.github.io]-[/usr/share/bpftrace/tools] └─$
再次运行,我们可以获取到匿名内存对应的进程相关的数据
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 ┌──[root@liruilongs.github.io]-[/usr/share/bpftrace/tools] └─$./ffaults1.bt Attaching 2 probes... ^CCOMM PID FILE FAULTS @[anon2mmap, 14655, ld.so.cache]: 1 @[bash, 14655, ld-linux-x86-64.so.2]: 2 @[bash, 13566, libc.so.6]: 2 @[bash, 13566, bash]: 5 @[bash, 14655, libc.so.6]: 5 @[anon2mmap, 14655, anon2mmap]: 6 @[bash, 14655, bash]: 9 @[anon2mmap, 14655, ld-linux-x86-64.so.2]: 9 @[bash, 14655, anonymous]: 10 @[anon2mmap, 14655, libc.so.6]: 27 @[bash, 13566, anonymous]: 76 @[anon2mmap, 14655, anonymous]: 4109 ┌──[root@liruilongs.github.io]-[/usr/share/bpftrace/tools] └─$
页换出守护进程(kswapd)的跟踪 我们先来理解页换入操作是什么?当系统内存需求超过一定水平时,内核中的页换出守护进程(kswapd)就开始寻找可以释放的内存页. 类似一些编程语言的垃圾回收
1 2 3 [root@liruilongs.github.io ~] root 113 2 0 15:02 ? 00:00:00 [kswapd0] [root@liruilongs.github.io ~]
当系统内存剩余量低于低水位阈值(pages_low)时,内核的页换出守护进程(kswapd)会被唤醒并开始回收内存。
守护进程(kswapd)会释放以下列出的三种内存页之一:
文件系统页:从磁盘中读出并且是没有修改过的页(术语为有磁盘备份的页(backed by disk),这些页可以立即被释放,等需要的时候可以再读取回来这些页包括应用程序可执行代码、数据,以及文件系统的元数据等。被修改过的文件系统页:这些页被称为脏页,这些页需要先写回磁盘才能被释放。应用程序内存页:这些页被称为匿名页(anonymous memory),因为这些页不是来源于某个文件的。如果系统中有换页设备(swap device),那么这些页可以先存入换页设备,再被释放。将内存页写入换页设备(在 linux系统上)称为换页。
vmscan(8)’ 使用 vmscan 跟踪点来观察页换出守护进程(kswapd)的操作,该进程在系统内存压力上升时负责释放内存以便重用。
它通过跟踪内核 tracepoint,记录 slab 收缩(mm_shrink_slab)、直接内存回收(mm_vmscan_direct_reclaim)、cgroup 内存回收(mm_vmscan_memcg_reclaim)的开始和结束时间,计算各阶段耗时并生成直方图,同时统计唤醒 kswapd 守护进程(mm_vmscan_wakeup_kswapd)和页面写回(mm_vmscan_writepage)的次数。脚本每秒输出一次汇总数据,包括各阶段耗时(转换为毫秒)和事件计数,帮助分析系统内存回收性能与压力情况。
对应的代码地址:
https://github.com/brendangregg/bpf-perf-tools-book/blob/master/originals/Ch07_Memory/vmscan.bt
这里我们使用 stress-ng 来模拟内存负载,唤醒 kswapd 守护进程
1 2 3 4 5 [root@liruilongs.github.io ~] stress-ng: info: [1377500] setting to a 60 second run per stressor stress-ng: info: [1377500] dispatching hogs: 4 vm stress-ng: info: [1377500] successful run completed in 60.56s (1 min, 0.56 secs) [root@liruilongs.github.io ~]
每秒输出的列包括如下几个:
S-SLABms:收缩 slab 所花的全部时间,以毫秒为单位。这是从各种内核缓存中量回收内存。D-RECLAIMms:直接回收所花的时间,以毫秒为单位。这是前台回收过程在此期间内存被换入磁盘中,并且内存分配处于阻塞状态。(需要 重点关注)M-RECLAIMms:内存 cgroup 回收所花的时间,以毫秒为单位。如果使用了内存cgroups,此列显示当cgroup超出内存限制,导致该cgroup进行内存回收的时间。KSWAPD:kswapd 唤醒的次数。WRITEPAGE:kswapd 写入页的数量。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 [root@liruilongs.github.io tools] Attaching 10 probes... TIME S-SLABms D-RECLAIMms M-RECLAIMms KSWAPD WRITEPAGE 06:49:10 10 1136 0 11 3 06:49:11 4 470 0 3 0 06:49:12 3 235 0 1 0 06:49:14 1 32 0 3 0 06:49:14 0 0 0 0 0 06:49:15 7 1518 0 8 2 06:49:16 13 3587 0 25 2 06:49:17 2 381 0 4 0 06:49:18 0 0 0 0 0 06:49:19 5 439 0 7 0 06:49:20 4 1009 0 10 0 06:49:21 6 738 0 8 1 06:49:22 5 375 0 5 0 06:49:23 4 440 0 6 0 06:49:24 4 375 0 8 0 06:49:25 4 350 0 4 1 06:49:26 4 285 0 4 0 06:49:27 5 336 0 3 1 06:49:28 0 0 0 0 0 。。。。。 06:49:35 0 0 0 0 0 ^C
直接内存回收的直方图
256K-512K 纳秒(0.256-0.5 毫秒)区间出现 4272 次,占比最高,是主要耗时区间,512K-1M 纳秒(0.5-1 毫秒)区间出现 3011 次,次高频,说明多数直接回收操作在 0.25-1 毫秒内完成,属于正常范围
1 2 3 4 5 6 7 8 9 10 11 12 13 @direct_reclaim_ns: [64K, 128K) 31 | | [128K, 256K) 1976 |@@@@@@@@@@@@@@@@@@@@@@@@ | [256K, 512K) 4272 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@| [512K, 1M) 3011 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ | [1M, 2M) 918 |@@@@@@@@@@@ | [2M, 4M) 193 |@@ | [4M, 8M) 112 |@ | [8M, 16M) 45 | | [16M, 32M) 2 | | [32M, 64M) 1 | | [64M, 128M) 55 | | [128M, 256M) 2 | |
slab 收缩(shrink_slab_ns)耗时分布
256-512 纳秒区间出现 254921 次,占绝对主导(几乎所有操作,说明 slab 收缩操作耗时极短(仅 0.25-0.5 微秒),效率极高
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 @shrink_slab_ns: [128, 256) 2494 | | [256, 512) 254921 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@| [512, 1K) 18830 |@@@ | [1K, 2K) 829 | | [2K, 4K) 168 | | [4K, 8K) 95 | | [8K, 16K) 85 | | [16K, 32K) 48 | | [32K, 64K) 11 | | [64K, 128K) 2 | | [128K, 256K) 0 | | [256K, 512K) 0 | | [512K, 1M) 0 | | [1M, 2M) 1 | | [root@liruilongs.github.io tools]
那些进程存在直接回收延迟? drsnoop(8)’是一个 BCC 工具,用来跟踪内存释放过程中的直接回收部分,可以显示受到影响的进程,以及对应的延迟:直接回收所需的时间。这可以用来定量分析在内存受限的系统中对应用程序的性能影响。
这里的直接回收(Direct Reclaim),即当应用程序尝试分配内存时,若当前内存不足且后台回收未能及时补充,内核会直接阻塞当前进程,同步执行内存回收操作(如扫描页面、释放缓存、交换数据到磁盘等),直至满足分配需求。这种回收方式会对进程的运行造成延迟,即 “直接回收延迟”。
这个工具内部跟踪的是 mm_vmscan_direct_reclaim_begin 和 mm_vmscan_direct_reclaim_end 跟踪点。这些应该都是低频事件(仅在短时间内集中出现),所以这里的额外消耗可以忽略不计。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 [root@liruilongs.github.io tools] COMM PID LAT(ms) PAGES stress-ng 1381737 1.05 62 stress-ng 1381738 1.18 59 stress-ng 1381738 0.31 42 ........ stress-ng 1381740 0.15 65 xfce4-terminal 32026 0.07 33 stress-ng 1381740 0.05 32 stress-ng 1381740 0.05 32 xfce4-terminal 32026 0.07 32 xfce4-terminal 32026 0.06 32 stress-ng 1381740 0.06 32 .............
stress-ng(PID 1381737~1381740)持续触发回收,单次回收 32-80页(128KB-320KB),延迟多数在 0.05ms-2.68ms 之间。这表明内存压力大:进程频繁申请内存,触发内核强制回收。xfce4-terminal(PID 32026)也有回收事件,但延迟较低(0.06-0.07ms),回收量小(32-33页)
可以通过 LAT(ms)/PAGES,做回收效率对比,高延迟低效率,如 stress-ng 的 2.68ms 仅回收 40页 → 回收效率低(阻塞时间长,释放内存少)
哪些进程阻塞于页换入操作? swapin(8)展示了哪个进程正在从换页设备中换入页,前提是系统中有正在使用的换页设备。这里需要提前确认交换分区,确保交换分区是开启状态
1 2 3 4 5 [root@liruilongs.github.io tools] [root@liruilongs.github.io tools] [root@liruilongs.github.io tools] NAME TYPE SIZE USED PRIO /dev/dm-1 partition 4G 0B -2
这个工具使用kprobes 来跟踪 swap_readpage() 内核函数,这会在触发换页所在的进程上下文中运行
这里任然使用上面的内存压测工具
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 [root@liruilongs.github.io tools] Attaching 2 probes... 06:58:08 @[xfce4-terminal, 32026]: 2 @[stress-ng, 1380727]: 1034 06:58:09 @[xfce4-terminal, 32026]: 1 @[xfsettingsd, 1736]: 1 @[xfdesktop, 1758]: 14 @[xfce4-panel, 1743]: 22 @[xfwm4, 1710]: 24 @[stress-ng, 1380727]: 221 06:58:10 @[xfwm4, 1710]: 4 @[xfdesktop, 1758]: 5 @[xfce4-terminal, 32026]: 9 @[xfce4-panel, 1743]: 91 @[stress-ng, 1380727]: 421 06:58:11 @[xfce4-terminal, 32026]: 1 @[xfce4-panel, 1743]: 13 @[stress-ng, 1380727]: 800 06:58:12 06:58:13 @[xfwm4, 1710]: 2 @[ibus-extension-, 2124]: 4 @[xfce4-terminal, 32026]: 7 @[xfdesktop, 1758]: 25 @[stress-ng, 1380727]: 489 06:58:14 @[xfce4-terminal, 32026]: 14 @[xfce4-panel, 1743]: 36 @[stress-ng, 1380727]: 963 06:58:15 ^C @[ibus-extension-, 2124]: 2 @[xfce4-terminal, 32026]: 4 @[xfce4-panel, 1743]: 19 @[ibus-x11, 2126]: 100 @[stress-ng, 1380727]: 1349 [root@liruilongs.github.io tools]
stress-ng 是主要内存压力源,单秒 Swap In 峰值达 1349 次,说明其持续申请内存并触发频繁换页,初期仅 stress-ng 高负载,后期扩散至桌面进程,表明物理内存资源逐步耗尽
大页的缺页错误跟踪 hfaults(8)’通过跟踪巨页相关的缺页错误信息,按进程展示详细信息,同时可以用来确保巨页确实被启用了。
代码地址
https://github.com/brendangregg/bpf-perf-tools-book/blob/master/originals/Ch07_Memory/hfaults.bt
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 #!/usr/local/bin/bpftrace /* * hfaults - Count huge page faults by process. * * See BPF Performance Tools, Chapter 7, for an explanation of this tool. * * Copyright (c) 2019 Amer Ather. * Licensed under the Apache License, Version 2.0 (the "License" ). * This was originally created for the BPF Performance Tools book * published by Addison Wesley. ISBN-13: 9780136554820 * When copying or porting, include this comment. */ BEGIN { printf ("Tracing Huge Page faults per process... Hit Ctrl-C to end.\n" ); } kprobe:hugetlb_fault { @[pid, comm] = count(); }
大页映射既可以用于文件映射,也可以用于匿名映射,具体取决于使用的场景和参数,使用上面的工具,在这之前我们需要做一些准备工作
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 ┌──[root@liruilongs.github.io]-[~/bpfdemo/mmapdev] └─$grep -i huge /proc/meminfo | grep -i size Hugepagesize: 2048 kB ┌──[root@liruilongs.github.io]-[~/bpfdemo/mmapdev] └─$sysctl -a | grep huge vm.hugetlb_optimize_vmemmap = 0 vm.hugetlb_shm_group = 0 vm.nr_hugepages = 0 vm.nr_hugepages_mempolicy = 0 vm.nr_overcommit_hugepages = 0 ┌──[root@liruilongs.github.io]-[~/bpfdemo/mmapdev] └─$free -h total used free shared buff/cache available Mem: 15Gi 12Gi 2.8Gi 3.0Mi 419Mi 3.0Gi Swap: 2.0Gi 337Mi 1.7Gi ┌──[root@liruilongs.github.io]-[~/bpfdemo/mmapdev] └─$sysctl -w vm.nr_hugepages=50 vm.nr_hugepages = 50 ┌──[root@liruilongs.github.io]-[~/bpfdemo/mmapdev] └─$free -h total used free shared buff/cache available Mem: 15Gi 12Gi 2.7Gi 3.0Mi 419Mi 2.9Gi Swap: 2.0Gi 337Mi 1.7Gi ┌──[root@liruilongs.github.io]-[~/bpfdemo/mmapdev] └─$sysctl -a | grep huge vm.hugetlb_optimize_vmemmap = 0 vm.hugetlb_shm_group = 0 vm.nr_hugepages = 50 vm.nr_hugepages_mempolicy = 50 vm.nr_overcommit_hugepages = 0 ┌──[root@liruilongs.github.io]-[~/bpfdemo/mmapdev] └─$mkdir -p /dev/hugepages ┌──[root@liruilongs.github.io]-[~/bpfdemo/mmapdev] └─$mount -t hugetlbfs -o pagesize=2M none /dev/hugepages
上面的命令主要完成了大页内存(Huge Pages)的配置与挂载,具体操作如下:
首先通过grep命令确认系统默认大页大小为2048KB(2MB);接着用sysctl查看大页相关参数,此时vm.nr_hugepages为0,意味着未分配大页内存;随后执行sysctl -w vm.nr_hugepages=50,为系统分配50个大页,每个大小2MB,共100MB内存,此时free -h显示可用内存减少约100MB;
接着通过sysctl -a验证大页分配成功,nr_hugepages和nr_hugepages_mempolicy均变为50;最后创建/dev/hugepages目录,并使用mount命令将大页文件系统(hugetlbfs)挂载到该目录,指定页大小为2MB,以便后续通过该目录使用大页内存。
下面是一个 文件内存映射使用大页的 Demo,可以看到分配2个大页,一个大页 2MB,两个 4MB
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 ┌──[root@liruilongs.github.io]-[~/bpfdemo] └─$cat hug2mmap.c #include <stdio.h> #include <stdlib.h> #include <sys/mman.h> #include <fcntl.h> #include <unistd.h> #include <string.h> #define MAP_SIZE (4 * 1024 * 1024) int main () int fd; char *map ; char path[] = "/dev/hugepages/test_huge" ; fd = open(path, O_CREAT | O_RDWR, 0666 ); if (fd == -1 ) { perror("open" ); return EXIT_FAILURE; } if (ftruncate(fd, MAP_SIZE) == -1 ) { perror("ftruncate" ); close(fd); return EXIT_FAILURE; } map = mmap(NULL , MAP_SIZE, PROT_READ | PROT_WRITE, MAP_SHARED, fd, 0 ); if (map == MAP_FAILED) { perror("mmap" ); close(fd); unlink(path); return EXIT_FAILURE; } memset (map , 'A' , MAP_SIZE); munmap(map , MAP_SIZE); close(fd); unlink(path); return 0 ; }
执行 Demo后观察 HugePages 相关的指标数据,确认是否使用成功
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 ┌──[root@liruilongs.github.io]-[~/bpfdemo] └─$vim hug2mmap.c ┌──[root@liruilongs.github.io]-[~/bpfdemo] └─$gcc -g hug2mmap.c -o hug2mmap ┌──[root@liruilongs.github.io]-[~/bpfdemo] └─$./hug2mmap ┌──[root@liruilongs.github.io]-[~/bpfdemo] └─$./hug2mmap hugetlbfs on /dev/hugepages type hugetlbfs (rw,relatime,pagesize=2M) Huge pages usage: AnonHugePages: 20480 kB ShmemHugePages: 0 kB FileHugePages: 0 kB HugePages_Total: 50 HugePages_Free: 48 HugePages_Rsvd: 0 HugePages_Surp: 0 Hugepagesize: 2048 kB Hugetlb: 102400 kB 50
分配了 50 个,使用 2个,空闲大页数为 48 个
1 2 HugePages_Total: 50 HugePages_Free: 48
hfaults 工具跟踪,可以看到两次大页的缺页异常
1 2 3 4 5 6 7 ┌──[root@liruilongs.github.io]-[/usr/share/bpftrace/tools] └─$./hfaults.bt Attaching 2 probes... Tracing Huge Page faults per process... Hit Ctrl-C to end. ^C @[2311, hug2mmap]: 2
限制内存使用量 今天和小伙伴分享一些Linux 内存限制相关知识,主要涉及如何配置以及什么情况下需要配置,我们知道内存属于不可压缩资源,当没有那么多的物理内存可以映射,进程都无法启动,所以为了公平,亦或是考虑部分进程 Qos 级别,一般情况下会对进程进行内存限制,即保证机器上的多个进程不会因为业务对基础资源的弹性要求,相互影响,比如类似FTP进程的内存泄露问题影响到核心业务服务触发 OOM ,甚至直接被OOM killer 掉。
简单介绍,关于内存资源限制在 Linux 中,一般按照限制手段来划分的话,分为
内核参数(包括启动配置)限制: 临时修改交换分区频率sysctl -w vm.swappiness=10, 启动引导配置大页参数grubby --update-kernel=ALL --args="hugepagesz=1G hugepages=10"
Cgroup(包括systemd)限制: 通过 Cgroup 的 memory 子系统限制 /sys/fs/cgroup/memory/myapp/memory.limit_in_bytes,MemoryMax=1G
ulimit 限制: ulimit -v 2097152
三种方式,按照限制类型划分,一般分为
系统内存限制: 比如修改内核参数sysctl -w vm.overcommit_memory=2 禁止过度分配虚拟内存
进程内存限制: Systemd 单元限制进程物理内存不超过 1G MemoryMax=1G
用户会话内存限制: echo "john hard as 2097152" >> /etc/security/limits.conf 限制用户 john 的进程最大虚拟内存(地址空间)为 2 GB
如果按照具体的内存种类划分,可以分为:
物理、虚拟内存限制: 硬限制物理内存大小 memory.limit_in_bytes, 会话级别虚拟内存限制 ulimit -v 数据段,数据栈限制: ulimit -d 262144 设置数据段的最大值
数据缓存区: 释放内存缓存区设置 vm.drop_caches,网络IO 相关缓存区配置 net.ipv4.tcp_rmem
大页,脏页相关内存页限制:大页大小 vm.nr_hugepages
Cgroup Cgroup(Control Groups)最早由 google 开发,后来内置到了 Linux 内核中,是Linux kernel(Linux内核)的一项功能,目前是很多虚拟化容器技术的底层核心技术。
在一个系统中运行的层级制进程组,Cgroup 可对其进行资源分配(如CPU时间、系统内存、网络带宽或者这些资源的组合)。
通过使用cgroup ,系统管理员在分配、排序、拒绝、管理和监控系统资源等方面,可以进行精细化控制。硬件资源可以在应用程序和用户间智能分配,从而增加整体效率。
Cgroup可对进程进行层级式分组并标记,并对其可用资源进行限制。通过将cgroup层级系统与systemd单位树捆绑, Linux 可以把资源管理设置从进程级别移至应用程序级别。
可以使用systemctl指令,或者通过修改systemd单位文件来管理系统资源。
为了控制重要的内核资源,systemd 会自动挂载/sys/fs/cgroup 目录实现 cgroup 分层架构,Linux 内核的资源管理器,也叫 CGroup 子系统,代表某一种单一资源(如 CPU 时间或内存等
Linux 内核提供了一系列资源管理器,由 systemd 自动挂载。如果需要查看已经挂载的资源管理器列表,可以参考/proc/cgroups
内存子系统位于其中:
memory: 对 cgroup 中的任务使用内存量进行限制,并且自动生成任务占用内存资源的报告
在安装了 kernel-doc 软件包后,可以在/usr/share/doc/kernel-doc-<version>/Documentation/cgroup 目录下找相关管理器的说明文档,从而配置合适的资源限制
1 2 3 4 5 6 7 8 9 10 11 ┌──[root@liruilongs.github.io]-[/usr/share/doc/kernel-doc-4.18.0/Documentation/cgroup-v1] └─$ls 00-INDEX cgroups.txt cpusets.txt freezer-subsystem.txt memcg_test.txt net_cls.txt pids.txt blkio-controller.txt cpuacct.txt devices.txt hugetlb.txt memory.txt net_prio.txt rdma.txt ┌──[root@liruilongs.github.io]-[/usr/share/doc/kernel-doc-4.18.0/Documentation/cgroup-v1] └─$ll total 184 。。。。。。。。。。。。。。。。 -r--r--r--. 1 root root 8480 Mar 27 2020 memcg_test.txt -r--r--r--. 1 root root 37743 Mar 27 2020 memory.txt ................
简单的信息可以通过索引文件的了解
1 2 3 4 5 6 7 8 9 10 ┌──[root@liruilongs.github.io]-[/usr/share/doc/kernel-doc-4.18.0/Documentation/cgroup-v1] └─$cat 00-INDEX 。。。。。。。 memcg_test.txt - Memory Resource Controller; implementation details. memory.txt - Memory Resource Controller; design, accounting, interface, testing. 。。。。。。。。。。。。。。。。。。。。。 ┌──[root@liruilongs.github.io]-[/usr/share/doc/kernel-doc-4.18.0/Documentation/cgroup-v1] └─$
Cgroup 限制内存资源常见的有两种,一种是 通过 systemd,一种是直接通过 cgroup 文件系统进行配置,这里我们先介绍通过 systemd 的方式配置,因为这种方式比较简单,而且可以做到进程级别的配置,而通过 cgroup 的方式,可以做到系统级别的配置,前提是当前Linux 机器使用 systemd,并且所有启动进程纳管到了 cgroup 子树,那么可以通过限制顶层树的资源限制,来实现整个系统的资源限制。
在 systemd 的 drop-in 文件文件[Service]段里面定义 MemoryLimit 值就可以限制你的程序所使用的内存,单位可以是K,M,G或T。
这里看一个以临时服务的方式运行 /bin/bash命令的Demo ,对 内存和CPU 进行限制, 并将其标准输入、标准输出、标准错误连接到当前的 TTY 设备上:
1 2 3 4 ┌──[root@liruilongs.github.io]-[~] └─$ systemd-run -p MemoryLimit=5M -p CPUShares=100 --unit=bash-limit --slice=bash-test -t /bin/bash Running as unit bash-limit.service. Press ^] three times within 1s to disconnect TTY.
在生成的 bash Service 中我们可以运行交互命令,查看当前 Service 的单元文件,MemoryLimit=5242880 ,即限制内存使用量 5M
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 ┌──[root@liruilongs.github.io]-[/] └─$ systemctl cat bash-limit.service [Service] CPUShares=100 [Unit] Description=/bin/bash [Service] Environment="TERM=xterm-256color" [Service] ExecStart= ExecStart=@/bin/bash "/bin/bash" [Service] MemoryLimit=5242880 。。。。。。。。。。。。。。。。。。。。。。。。
通过 systemctl status bash-limit.service 我们可以看到cgroup的相关信息
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 ┌──[root@liruilongs.github.io]-[/] └─$ systemctl status bash-limit.service ● bash-limit.service - /bin/bash Loaded: loaded (/run/systemd/system/bash-limit.service; static; vendor preset: disabled) Drop-In: /run/systemd/system/bash-limit.service.d └─50-CPUShares.conf, 50-Description.conf, 50-Environment.conf, 50-ExecStart.conf, 50-MemoryLimit.conf, 50-Slice.conf, 50-StandardError.conf, 50-StandardInput.conf, 50-StandardOutput.conf, 50-TTYPath.conf Active: active (running) since 六 2022-10-29 13:40:19 CST; 31s ago Main PID: 136529 (bash) Memory: 1.7M (limit : 5.0M) CGroup: /bash.slice/bash-test.slice/bash-limit.service ├─136529 /bin/bash └─136607 systemctl status bash-limit.service 10月 29 13:40:19 liruilongs.github.io systemd[1]: Started /bin/bash. ┌──[root@liruilongs.github.io]-[/] └─$ bash ┌──[root@liruilongs.github.io]-[/] └─$ bash
bash-limit.service 这个 service 的上级子树为 bash.slice 这个分组。
1 2 3 4 Memory: 1.7M (limit : 5.0M) CGroup: /bash.slice/bash-test.slice/bash-limit.service ├─136529 /bin/bash └─136607 systemctl status bash-limit.service
当然上面的配置方式实际上是基于 Cgroup 来实现的,Cgroup V1 版本和 V2 版本有些区别,当前机器环境的问题,我们只看一下 V1 的版本,MemoryLimit 参数可以控制Cgroup 内存控制器的 memory.limit_in_bytes Cgroup参数。
对于运行中的 service 可以直接通过set-property 的方式来修改
1 2 systemctl set-property httpd.service CPUShares=600 MemoryLimit=500M
下面为 system.slice 这个 Cgroup 分组下面 tuned Cgroup 内存相关资源限制,可以看到默认的情况下没有限制(memory.limit_in_bytes ),使用的最大值,这里的内存限制是物理内存,不是虚拟内存,
tuned 小伙伴们应该不陌生,一个开源的系统性能优化的服务,用于一些内核参数限制
1 2 3 4 5 6 7 8 9 10 11 ┌──[root@liruilongs.github.io]-[/sys/fs/cgroup/memory/system.slice] └─$cat tuned.service/memory. memory.events memory.kmem.tcp.failcnt memory.memsw.failcnt memory.qos_level memory.events.local memory.kmem.tcp.limit_in_bytes memory.memsw.limit_in_bytes memory.soft_limit_in_bytes memory.failcnt memory.kmem.tcp.max_usage_in_bytes memory.memsw.max_usage_in_bytes memory.stat memory.force_empty memory.kmem.tcp.usage_in_bytes memory.memsw.usage_in_bytes memory.swappiness memory.high memory.kmem.usage_in_bytes memory.min memory.usage_in_bytes memory.kmem.failcnt memory.limit_in_bytes memory.move_charge_at_immigrate memory.use_hierarchy memory.kmem.limit_in_bytes memory.low memory.numa_stat memory.kmem.max_usage_in_bytes memory.max_usage_in_bytes memory.oom_control memory.kmem.slabinfo memory.memfs_files_info memory.pressure_level
默认情况下,没有限制会显示最大值
1 2 3 ┌──[root@liruilongs.github.io]-[/sys/fs/cgroup/memory/system.slice] └─$cat tuned.service/memory.limit_in_bytes 9223372036854771712
配置方式我们可以通过上面的方式配置,通过 service unit 文件进行限制
限定最大可用内存为 1GB,添加 MemoryLimit 设定
1 2 ┌──[root@liruilongs.github.io]-[/usr/lib/systemd/system] └─$vim tuned.service
确认配置,加载配置文件,重启
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 ┌──[root@liruilongs.github.io]-[/usr/lib/systemd/system] └─$systemctl cat tuned.service [Unit] Description=Dynamic System Tuning Daemon After=systemd-sysctl.service network.target dbus.service Requires=dbus.service polkit.service Conflicts=cpupower.service auto-cpufreq.service tlp.service power-profiles-daemon.service Documentation=man:tuned(8) man:tuned.conf(5) man:tuned-adm(8) [Service] Type=dbus MemoryLimit=1G PIDFile=/run/tuned/tuned.pid BusName=com.redhat.tuned ExecStart=/usr/sbin/tuned -l -P Restart=on-failure [Install] WantedBy=multi-user.target ┌──[root@liruilongs.github.io]-[/usr/lib/systemd/system] └─$systemctl daemon-reload ┌──[root@liruilongs.github.io]-[/usr/lib/systemd/system] └─$systemctl restart tuned.service
再次查看 Cgroup 内存相关限制参数
1 2 3 4 5 ┌──[root@liruilongs.github.io]-[/usr/lib/systemd/system] └─$cat /sys/fs/cgroup/memory/system.slice/tuned.service/memory.limit_in_bytes 1073741824 ┌──[root@liruilongs.github.io]-[/usr/lib/systemd/system] └─$
生产环境,更多的是通过 drop-in 的方式定义文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 ┌──[root@liruilongs.github.io]-[/usr/lib/systemd/system] └─$vim tuned.service.d/50-MemoryLimit.conf ┌──[root@liruilongs.github.io]-[/usr/lib/systemd/system] └─$systemctl daemon-reload ┌──[root@liruilongs.github.io]-[/usr/lib/systemd/system] └─$systemctl restart tuned.service ┌──[root@liruilongs.github.io]-[/usr/lib/systemd/system] └─$systemctl cat tuned.service [Unit] Description=Dynamic System Tuning Daemon After=systemd-sysctl.service network.target dbus.service Requires=dbus.service polkit.service Conflicts=cpupower.service auto-cpufreq.service tlp.service power-profiles-daemon.service Documentation=man:tuned(8) man:tuned.conf(5) man:tuned-adm(8) [Service] Type=dbus PIDFile=/run/tuned/tuned.pid BusName=com.redhat.tuned ExecStart=/usr/sbin/tuned -l -P Restart=on-failure [Install] WantedBy=multi-user.target [Service] MemoryLimit=1G ┌──[root@liruilongs.github.io]-[/usr/lib/systemd/system] └─$
这里我们简单看一下,其他的 Cgroup 参数限制,部分参数在 Cgroup V2 中作了调整,感兴趣小伙伴可以看看去
核心内存限制
参数
作用
memory.limit_in_bytes物理内存硬限制 (单位:字节),超出会触发 OOM Killer。
memory.memsw.limit_in_bytes物理内存 + swap 总限制 (需内核启用 swapaccount=1)。
memory.soft_limit_in_bytes内存软限制 ,系统优先回收超过此值的内存,但不会强制杀死进程。
内核内存控制
参数
作用
memory.kmem.limit_in_bytes内核内存(如 slab、dentry 缓存)的硬限制 。
memory.kmem.tcp.limit_in_bytesTCP 缓冲区内存的硬限制 (如 TCP socket 发送/接收缓冲区)。
内存回收与行为控制
参数
作用
memory.force_empty强制释放内存缓存 (写入 0 触发)。
memory.swappiness调整内存回收策略 (值越高,系统越积极使用 swap)。
memory.oom_control控制 OOM Killer 行为 (0 表示启用 OOM Killer,1 表示禁用)。
memory.move_charge_at_immigrate进程迁移时是否转移内存占用 (1 表示转移)。
高级功能
参数
作用
memory.high内存使用软限制 (v1 中较少使用,v2 中更常见)。
memory.low内存保护阈值 ,系统尽量避免回收低于此值的内存。
memory.pressure_level内存压力事件通知 (需配合 cgroup.event_control 使用)。
对于这部分参数的配置,可以直接找到对应的 Cgroup 文件进行修改
1 2 # 限制 TCP 缓冲区为 100MB echo "100M" > memory.kmem.tcp.limit_in_bytes
ulimit 对于多用户的系统不限制资源本身可能就是一种不公平, 限制系统资源比较老的方式是使用 ulimit,由 PAM 模块在登录和会话启动时强制实施,ulimit 命令是bash 内置命令,主要限制了 shell 及其子进程可用的资源
在/etc/pam.d/system-auth 文件中调用了 pam_limits 模块,此模块读取 /etc/security/limits.conf 和/etc/security/limits.d/,按配置文件设置资源限制。 查看模块帮助文档 man pam limits
/etc/pam.d/system-auth 是什么?
/etc/pam.d/system-auth 是一个 PAM(Pluggable Authentication Modules)配置文件。在 Linux 系统中,PAM 提供了一种灵活的方式来配置用户认证、授权和会话管理
该文件是一个包含 PAM 配置行的文本文件,用于定义不同的认证、授权和会话模块及其参数。PAM 模块负责处理用户登录、密码验证、权限检查等操作。
查看文件中资源限制相关的模块,有时候我们做一些基线整改,可能需要修改该文件的相关配置
1 2 3 4 5 ┌──[root@liruilongs.github.io]-[~] └─$cat /etc/pam.d/system-auth | grep pam_limits session required pam_limits.so ┌──[root@liruilongs.github.io]-[~] └─$
在PAM配置中,pam_limits.so 模块被要求进行会话限制
PAM(Pluggable Authentication Modules)是一个用于对用户进行认证的系统级框架。pam_limits.so 模块是 PAM 框架的一部分,它用于设置会话级别的资源限制,例如进程可打开的文件数、进程可使用的内存等。
ulimit 命令是用于限制用户级别资源的工具,它通常用于控制 shell 进程及其子进程的资源使用。修改 ulimit 值只会对当前 shell 会话有效,对其他用户或系统进程不会产生影响(不一定)
通过 ulimit 是限制系统资源的一种途径,ulimit 支持 hard 和 soft 限制
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23
普通用户可以设置自己的软限制,但不能高于硬限制。可以使用 ulimit -a 查看资源限制列表
软限制 (soft maxlogins):软限制是一个警告阈值,当达到或超过该限制时,系统会发出警告信息,但不会阻止用户登录。硬限制 (hard maxlogins):硬限制是一个严格的限制,当达到或超过该限制时,系统将阻止用户登录。
1 2 3 4 5 6 7 8 ┌──[root@liruilongs.github.io]-[~] └─$ulimit -Hn 262144 ┌──[root@liruilongs.github.io]-[~] └─$ulimit -Sn 1024 ┌──[root@liruilongs.github.io]-[~] └─$
当指定限制数时限制,不指定时输出当前设置
通过配置文件的方式对登录次数进行限制,配置 kiosk 组 在多个终端中只能同时登录 2 次
1 2 3 4 5 6 ┌──[root@liruilongs.github.io]-[~] └─$cat /etc/security/limits.conf | grep -v ^ @kiosk soft maxlogins 2 @kiosk hard maxlogins 2 ┌──[root@liruilongs.github.io]-[~] └─$
涉及到内存相关的资源限制
memlock:最大锁定内存地址空间限制(以 KB 为单位)rss:最大常驻集大小限制(以 KB 为单位)物理内存stack:最大堆栈大小限制(以 KB 为单位)as:地址空间限制(以 KB 为单位)虚拟内存msgqueue:POSIX 消息队列使用的最大内存限制(以字节为单位)
配置虚拟内存限制可以通过 ulimit 进行会话基本的虚拟内存设置,下面是一个 Demo,仅对 当前 Shell 及其子进程 生效 as 虚拟地址空间限制,以 KB 为单位
1 2 3 4 5 ┌──[root@liruilongs.github.io]-[~] └─$ulimit -v 8186 ┌──[root@liruilongs.github.io]-[~] └─$ls ls: error while loading shared libraries: libc.so.6: failed to map segment from shared object
修改 as 的大小之后,提示 ls 命令无法加载共享库 libc.so.6,并且无法从共享对象映射段
永久配置(全局或用户级)需要修改 /etc/security/limits.conf, 感兴趣小伙伴可以看看我之前的博文,生效条件:用户重新登录后生效。
1 2 3 liruilong hard as 819200 liruilong soft as 409600
其他的一些限制项,也可以通过上面的方式进行,比如内存锁定,最大栈,数据段等内存相关的限制
内核参数 通过内核参数对内存的限制主要是一些缓存区的内存占用限制,以及部分 OOM 和 内存使用策略的修改,内存页分配限制策略等
这里关于怎么修改内核参数以及内核参数的加载方式,可以参考我之前的博文,这里就不再赘述了
缓存区内存限制
下面为通过关键字过滤部分的内核参数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 [root@developer ~] kernel.bind_memcg_blkcg_enable = 1 net.core.optmem_max = 81920 net.core.rmem_default = 212992 net.core.rmem_max = 212992 net.core.wmem_default = 212992 net.core.wmem_max = 212992 net.ipv4.fib_sync_mem = 524288 net.ipv4.igmp_max_memberships = 20 net.ipv4.tcp_mem = 78777105039157554 net.ipv4.tcp_rmem = 40961310726291456 net.ipv4.tcp_wmem = 4096163844194304 net.ipv4.udp_mem = 157557210078315114 net.ipv4.udp_rmem_min = 4096 net.ipv4.udp_wmem_min = 4096 vm.hugepage_pmem_allocall = 0 vm.hugetlb_optimize_vmemmap = 0 vm.lowmem_reserve_ratio = 256256320 vm.memcg_qos_enable = 0 vm.memcg_swap_qos_enable = 0 vm.memory_failure_early_kill = 0 vm.memory_failure_recovery = 1 vm.nr_hugepages_mempolicy = 0 vm.overcommit_memory = 0 [root@developer ~]
缓存区的话,一般用的比较多的是网络方面的,比如 TCP,UDP,Stock 等。这部分参数没有固定的值,一般根据机器使用场景动态设置
在上面的输出中,前部位为 socket 级别的网络缓存区限制,socket接受和发送数据的缓存的最大值,这里的配置往往结合 BDP 进行配置,感兴趣小伙伴可以看看我之前网络调优的博文。
1 2 3 4 5 net.core.optmem_max = 81920 net.core.rmem_default = 212992 net.core.rmem_max = 212992 net.core.wmem_default = 212992 net.core.wmem_max = 212992
后部分为 TCP/UDP 级别的网络缓存区限制,TCP 缓冲区的大小应根据系统和网络的需求进行调整。较大的缓冲区可以提高网络性能,特别是在高负载或高延迟的网络环境中。但是,过大的缓冲区可能会导致内存占用增加或延迟问题。
net.ipv4.tcp_rmem 和 net.ipv4.tcp_wmem 用于配置 TCP 套接字的接收缓冲区和发送缓冲区的大小。
1 2 3 4 net.ipv4.tcp_rmem = 40961310726291456 net.ipv4.tcp_wmem = 4096163844194304 net.ipv4.udp_rmem_min = 4096 net.ipv4.udp_wmem_min = 4096
下面的两个为 系统级别内存限制,单位是Page 内存页,4K,分别代表了TCP和UDP的系统层面内存限制的值,即网络连接的内存分配,包括三列:min,pressure,max.
1 2 net.ipv4.tcp_mem = 78777 105039 157554 net.ipv4.udp_mem = 157557 210078 315114
这里格式有点问题,我们换一个方式查看
1 2 3 [root@developer ~] 78777 105039 157554 [root@developer ~]
内存超售限制
下面这组内核参数用于限制内存的超售问题,内存的分配和使用是两个阶段,在分配的时候是虚拟内存,而且实际使用才会分配物理内存,对于虚拟内存的分配,可以是一个很大的值,但是物理内存的分配,是有限制的,如果分配的虚拟内存大于物理内存,那么就会导致内存超售,那么这个时候,就需要限制内存的超售问题,避免内存超售导致系统崩溃。
1 2 3 4 5 [root@developer ~] vm.nr_overcommit_hugepages = 0 vm.overcommit_kbytes = 0 vm.overcommit_memory = 0 vm.overcommit_ratio = 50
vm.overcommit_memory = 0 :控制内核的内存超分配策略,决定是否允许进程申请超过物理内存 + Swap 的空间。
0(默认):启发式超分配(Heuristic Overcommit)。内核根据当前空闲内存、可回收缓存(PageCache/SLAB)和 Swap 综合判断是否允许分配。若申请量显著超过可用资源则拒绝。
1:无条件允许超分配(Always Overcommit)。来者不拒,但可能因实际内存不足触发 OOM Killer。
2:禁止超分配(Never Overcommit)。严格限制分配总量 ≤ (物理内存 × overcommit_ratio%) + Swap。
vm.overcommit_ratio = 50: 当 overcommit_memory=2 时,定义物理内存的可超配比例(默认值 50%)。 计算公式: CommitLimit = (物理内存 × overcommit_ratio / 100) + Swap
vm.overcommit_kbytes = 0:与 overcommit_ratio 互斥,直接指定超配的字节级上限(优先级高于 ratio)。
vm.nr_overcommit_hugepages = 0:控制标准大页(HugePages)的超配数量,允许临时分配超出 vm.nr_hugepages 预设值的大页。
上面讲到了大页,这里我们顺便看看内存页相关的内存限制
内存页限制
hugepages 用于限制分配的大页数量,这里的大页指的是标准大页,即 2MB 的大页,
1 sysctl -w vm.nr_hugepages=1024
如果需要自定义大页的大小,比如 1GB 的大页,需要通过 hugepagesz 来进行限制,一般启动时通过GRUB配置
1 hugepagesz=1G hugepages=4 default_hugepagesz=1G
关于内存页,内核相关的参数中还有透明大页的配置,比如透明大页的开启,khugepaged 进程的扫描频率等等,感兴趣的小伙伴可以看看我之前关于大页的博文
下面为脏页/换页/内存回收与保留相关参数的内存限制
脏页指内存中已被修改但未写入磁盘的数据页。内核通过以下参数控制其回写行为:
1 2 3 4 5 6 7 8 [root@developer ~] vm.dirty_background_bytes = 0 vm.dirty_background_ratio = 10 vm.dirty_bytes = 0 vm.dirty_expire_centisecs = 3000 vm.dirty_ratio = 30 vm.dirty_writeback_centisecs = 500 vm.dirtytime_expire_seconds = 43200
下面为交换分区使用限制
1 2 3 vm.memcg_swap_qos_enable = 0 vm.swap_extension = 0 vm.swappiness = 30
还有两个特殊的参数需要单独说明一下:
vm.min_free_kbytes:系统保留的最小空闲内存(单位 KB),用于应对突发需求vm.watermark_scale_factor:调整内存回收敏感度(默认 10,范围 1-1000)。
1 2 3 4 5 [root@developer ~] vm.min_free_kbytes = 45056 [root@developer ~] vm.watermark_scale_factor = 10 [root@developer ~]
OOM 相关内存限制
下面为OOM相关,的内存限制,关于 OOM 是什么,什么原理不是本文重点,小伙伴可以看看我之前的博文
1 2 3 4 5 6 [root@developer ~] vm.enable_oom_killer = 1 vm.oom_dump_tasks = 1 vm.oom_kill_allocating_task = 0 vm.panic_on_oom = 0 [root@developer ~]
NUMA内存限制
1 2 3 4 5 [root@developer ~] vm.zone_reclaim_mode = 0 [root@developer ~] vm.min_unmapped_ratio = 1 [root@developer ~]
OOM Killer 认知 OOM Killer 机制如何工作? OOM Killer(Out-Of-Memory Killer)是内核在系统内存严重不足时触发的紧急机制,通过终止进程释放内存以维持系统稳定,每个进程有一个 OOM 相关的分数,终止进程的时候基于这个分数进行处理,有一些内核参数可以控制 OOM Killer 的行为,生产中考虑QOS可以进行相关的配置,当然更合理的方式是使用Cgroup对不同进程的内存资源进行限制,
OOMKiller 的工作原理是选择消耗最多内存的进程,该进程也被认为对系统操作最不重要。此选择过程基于多个因素,包括进程的内存使用情况、优先级以及运行的时间量。
一旦 OOMKiller 选择要终止的进程,它就会向该进程发送信号,要求它正常终止。如果进程不响应信号,内核将强制终止进程并释放其内存。
OOMKiller 是一种最后的手段机制,仅在系统面临内存不足的危险时才调用。虽然它可以帮助防止系统因内存耗尽而崩溃,但重要的是要注意,终止进程可能导致数据丢失和系统不稳定。因此,建议配置系统以避免 OOM 情况,例如,通过监视内存使用情况、设置资源限制和优化应用程序中的内存使用情况。
可以通过调整内核参数来修改 ,OOM 是否自动触发。如果内核参数sysctl vm.panic_on_oom设置为1而不是0,内核将会发生 panic,即直接摆烂,什么时候挂掉算什么时候。默设置0时.即自动启动OOM killer
1 2 3 4 ┌──[root@liruilongs.github.io]-[~] └─$ sysctl vm.panic_on_oom vm.panic_on_oom = 0
如果你希望强制的执行OOM Killer ,可以echo f > /proc/sysrq-trigger,但请记住,至少会有一个进程被杀死。
1 2 3 4 [root@ecs-liruilong ~] Message from syslogd@ecs-liruilong at Aug 1 14:32:18 ... kernel:[340648.118967] Kernel panic - not syncing: Out of memory: system-wide panic_on_oom is enabled
输出将被发送到dmesg。
对于 OOM Killer 的触发进程和被 Kill 进程,内核会记录一些信息,这些信息可以通过dmesg命令查看。
1 2 3 [日 5月 11 15:41:12 2025] Out of memory: Killed process 39693 (stress-ng) total-vm:2410396kB, anon-rss:1896300kB, file-rss:4kB, shmem-rss:60kB, UID:0 pgtables:3772kB oom_score_adj:1000
在后台,Linux 内核为主机上运行的每个进程保持一个运行不良评分。此分数越高,进程被终止的可能性就越大。
1 2 [root@ecs-liruilong ~] 0
分数越高,进程越有可能被OOM杀手杀死。许多因素被用来计算这个分数:
VM大小(不是RSS大小),
进程所有子进程的累积VM大小,
nice值(正的nice值会给出更高的分数),
总运行时间(较长的总运行时间会降低分数),
运行用户(根进程会得到轻微的保护),
进程执行直接硬件访问,分数也会降低。
内核本身和PID1 (sysemd)是免疫的OOM杀手。
需要说明的是这个分数是无法被修改的,但是可以调整oom_score_adj的值,
在旧的内核版本中,这个值用 oom_adj 表示,通过的/proc/PID/oom_adj可以用来手动调整oom_score。配置该pid进程被oom killer杀掉的权重,oom_adj可以的值从-17到15,其中0表示不改变(默认),越高的权重,意味着更可能被oom killer选中,-17表示免疫(永远不会杀死)。
1 2 [root@ecs-liruilong ~] 0
新内核版本中,之前的参数已经废弃,可以使用/proc/PID/oom_score_adj来调整,范围是-1000到1000,-1000表示免疫OOM killer,1000表示优先被OOM killer杀死。
1 2 [root@ecs-liruilong ~] 0
也可以在服务启动时配置,通过systemd的OOMScoreAdjust参数,可以设置OOM的评分
1 2 3 4 5 6 7 cat > /etc/systemd/system/nginx.service.d/10-oom.conf << EOF [Service] # 设置OOM评分调整值 # 取值范围:-1000(最难被杀死)到1000(最易被杀死) # 这里设置为-500,适合重要但非核心的服务 OOMScoreAdjust=-500 EOF
OOM Killer 如何观测? 利用 Cgroup/dmesg 观测 OOM Killer 事件 传统的 OOM killer 历史数据查看一般通过内核日志查看,可以结合 Cgroup 相关内存子系统的事件计数器。
Cgroup 内存子系统有 OOM 相关的事件统计, memory.events 指标,是一个内存事件计数器:
只要系统使用了 systemd,那么就可以在对应的服务单元下找到对应的 内存事件统计
1 2 3 4 5 6 7 8 ┌──[root@liruilongs.github.io]-[/usr/lib/systemd/system] └─$cat /sys/fs/cgroup/memory/system.slice/tuned.service/memory.events low 0 high 0 limit_in_bytes 0 oom 0 ┌──[root@liruilongs.github.io]-[/usr/lib/systemd/system] └─$
具体的参数指标说明:
low: 低内存压力事件次数high: 高内存压力事件次数limit_in_bytes: 达到内存限制的次数oom: 这里的 OOM 指标为 OOM的触发次数。全为 0 表示无相关事件发生。
下面两个在上面的输出中没有,不同的内核版本,Cgroup版本对应的指标数据展示的不一样。
oom_kill: OOM killer 触发次数,属于此cgroup的进程被任何类型的00M杀手杀死的数量。oom_group_kill: 对应的 Cgroup group 被 OOM Killer 的次数。
内核日志dmesg 可以显示详细的 OOM killer 进程相关数据
利用 BPF/eBPF 观测 OOM Killer 事件 对于 BPF 的监控,主要通过 BPF 和 bpftrace 的 oomkill 工具,我们可以在触发 OOM killer 事件之后,观察到系统平均负载等一些其他的信息,原理是通过动态插桩内核函数 oom_kill_process(),捕获 OOM Killer 触发事件
当系统内存不足的时候,out_of_memory()被触发,然后调用oom_kill_process()杀掉进程
比如平均负载信息可以在 OOM 发生时提供整个系统状态的一些 上下文信息,展示出系统整体是正在变忙还是处于稳定状态,以及那个进程触发了 OOM Killer 和,被 OOM Killer 杀掉的进程是那个等数据。
这里不多讲,小伙伴可以看看上 BPF 监控内存部分有详细的描述
博文部分内容参考 © 文中涉及参考链接内容版权归原作者所有,如有侵权请告知 :)
《性能之巅 系统、企业与云可观测性(第2版)》
《 Red Hat Performance Tuning 442 》
© 2018-至今 liruilonger@gmail.com , All rights reserved. 保持署名-非商用-相同方式共享(CC BY-NC-SA 4.0)